
OPTIMAL PLANNING FOR AUTONOMOUS AGENTS
UNDER TIME AND RESOURCE UNCERTAINTY
Aur
´
elie Beynier, Laurent Jeanpierre, Abdel-Illah Mouaddib
Bd Marechal Juin, Campus II
BP5186, 14032 Caen Cedex, France
Keywords:
Decision Theory, Mobile robots, Autonomous Agents, Planning under Uncertainty.
Abstract:
In this paper we develop an approach for planning under time and resource uncertainty with task dependen-
cies. We follow the line of research described by (Bresina et al., 2002), overcoming limitations of existing
approaches: they only handle simple time constraints and assume a simple model of durations and resources’
uncertainty.In many domains, such as space applications (rovers, satellites), these assumptions are invalid. Our
approach considers temporal and resource constraints and fully deals with their uncertainty. From a mission
graph, we build a MDP that can be optimally solved by dynamic programming, even for large mission graphs.
1 INTRODUCTION
In this paper we develop an approach of planning un-
der time and resource uncertainty along the research
lines described in a challenge paper of (Bresina et al.,
2002). In that paper, authors claim that existing meth-
ods fail because they suffer from many limitations
where some of them consist of: (1) they only han-
dle simple time constraints, (2) they assume a sim-
ple model of uncertainty concerning action durations
and resource consumption. In many domains such as
space applications (rovers, satellites), these assump-
tions are not valid. We present an approach that re-
laxes those assumptions by using a model of tasks
with complex dependencies, uncertain execution time
and probabilistic resource consumptions. In this ap-
proach, we consider the following: (1) a mission is an
acyclic graph of tasks that expresses complex depen-
dencies between tasks, (2) a task has a temporal inter-
val during which it can be executed, (3) durations and
resource consumptions of tasks are uncertain. This
class of problems is found in some rover scenarios
where the objective of the rover is to maximize the
overall value of the mission: given the mission graph,
we want the mission to be executed optimally by an
autonomous agent.
The major objectives of future space missions (Es-
tlin et al., 1999; Bresina et al., 2002) will consist of
maximizing science return and enabling certain types
of activities by using a robust approach. To show
the significance of problems we deal with, let us give
some examples of robotic vehicles where we express
the different constraints we consider in this paper:
• Time windows: a number of tasks need to be
done at particular but approximate times: for exam-
ple “about noon”, “at sunrise”. There is no explicit
time window but we can represent these using time
windows or soft constraints on a precise time. Exam-
ples include atmospheric measurements (look at the
sun through the atmosphere must be done at sunrise,
sunset, and noon). Since the rover will be power-
constrained, most of the rover’s operations will oc-
cur between 10:00 and 15:00 to make sure that there
is enough sunlight to operate. Driving will certainly
happen during that part of the day. Communication
also has to start at a particular time since this re-
quires synchronization with Earth. There are opera-
tions that cannot be done outside of a time window
– night-time operations of cameras or daytime oper-
ations of the spectrometer. Other constraints can be
considered such as illumination constraints (which in-
volves time of day and position), setup times (warm-
up or cool-down delays for instruments), time separa-
tion between images to infer 3D shape from shadows.
• Precedence dependencies: a tasks usually has
preconditions that must hold before the agent can ex-
ecute it. For instance, instruments must be turned on
and calibrated, in order the agent to perform the mea-
surements. Such dependencies lead to precedence
constraints between the tasks.
182
Beynier A., Jeanpierre L. and Mouaddib A. (2006).
OPTIMAL PLANNING FOR AUTONOMOUS AGENTS UNDER TIME AND RESOURCE UNCERTAINTY.
In Proceedings of the Third International Conference on Informatics in Control, Automation and Robotics, pages 182-187
DOI: 10.5220/0001203901820187
Copyright
c
SciTePress
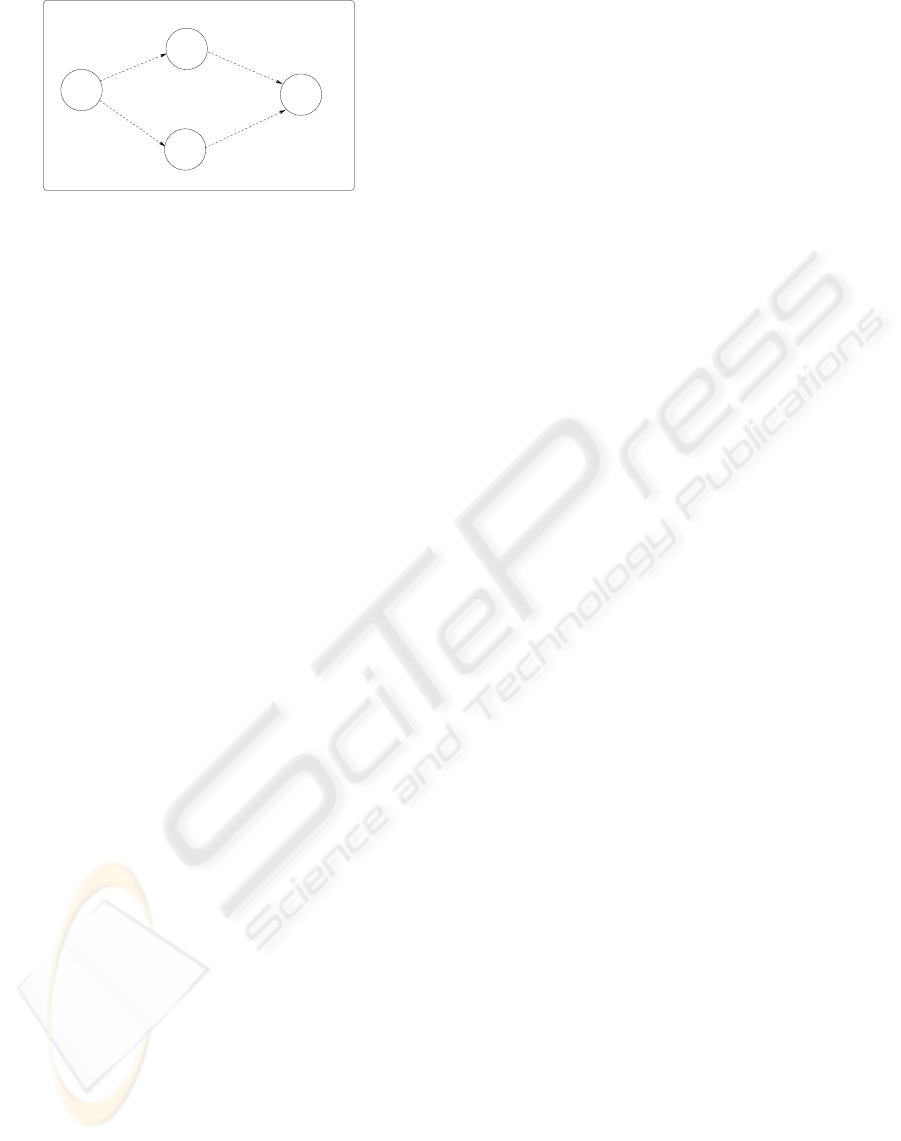
consum = {5 , 6}
consum. = { 4, 6, 7}
Move to
the target
Snap
the target
Atmospheric
measurement
consum = {3 , 4}
Send
data
consum. = {1, 2, 3}
durations = { 4, 5, 6}
durations = {1 , 2}
durations = {3, 4}
durations = {2 , 3}
Rini = 13
EST = 1, LET = 10
EST = 9, LET = 15
EST = 5, LET = 9
EST = 1, LET = 12
Figure 1: An acyclic graph of tasks.
• Bounded resources: many activities require
power and data storage.
In summary, these scenarios share common char-
acteristics such as: 1)Activities have an associated
temporal window. 2)Task durations and resource con-
sumptions are uncertain. 3)The temporal constraints
are, in general, soft. 4)Precedence dependencies be-
tween tasks exist. 5)The mission can be represented
by an acyclic graph. These scenarios are well suited
to space-rovers because of the communication delay
which prevents the agent from any interaction that
could help it to achieve its tasks. For example, com-
munication from Earth to Mars suffers from several
minutes delays, and requires synchronization. There-
fore missions generally include a whole workday, that
is around one hundred tasks to accomplish. Mission
plans are generally computed on Earth, transmitted to
the distant agent once a day, and then executed au-
tonomously during the rest of the day. However, even
if we focus mainly on rovers, the approach we present
in this paper can be applied to any problem formalized
as a dependency graph. We could apply it to cooking
a dinner; in this case, we would have a recipe to fol-
low, ingredients to buy and mix in the proper order,
and choices on which meal to prepare depending on
the remaining time before the guests arrival...
Existing work on planning under uncertainty for
rovers encounter difficulties in their application to real
problems because most of them handle only simple
time constraints (deadline) and instantaneous actions.
More sophisticated techniques have been developed
to deal with uncertain duration (Tsamardinos et al.,
2003; Vidal and Ghallab, 1996; Morris et al., 2001)
but they fail to optimally control the execution.
The requirements for a richer model of time and
actions are more problematic for those planning tech-
niques (Bresina et al., 2002). The techniques based
on MDP and POMDP representations can be used to
represent actions with uncertainty on their outcomes
(Mouaddib and Zilberstein, 1998; Cardon et al.,
2001) but they have difficulties when those actions in-
volve temporal dependencies and uncertain durations.
Given the temporal constraints of the rover problem,
which are not purely Markovian, the approach should
handle irregular multi-step transitions.
In this paper, we proposed a formalism that can
deal with temporal and resource constraints to rep-
resent realistic problems. Our approach deals with
uncertainty on task durations and resource con-
sumptions. Like Semi-Markov Decision Processes
(SMDPs) (Sutton et al., 1999), it considers different
possible durations for each task. We propose to for-
malize the problem using an MDP that allows for tem-
poral and resource constraints. This MDP is solved
optimally by dynamic programming. We demonstrate
that problems of a hundred tasks can be considered.
2 PRINCIPLES OF THE
APPROACH
Let’s consider a planetary rover that have a mission
to complete. First, it must move to a target. Then,
depending on the time and on available resources, it
can snap the target or complete atmospheric measure-
ments. To end its mission, the rover must send the
data it has collected. As shown in Figure 1, this small
mission can be represented by an acyclic graph. Each
node stands for a task t
i
and edges represent temporal
constraints: the rover must move to the target before
it can snap it. “Rini” is the initial resource rate. We
consider only “or” nodes : the agent must snap the tar-
get or complete atmospheric measurements. In order
to send the data, one of these predecessor tasks must
be completed. Temporal constraints are indicated by
the Earliest Start Time (EST) and the Latest End Time
(LET) of each task.
In the rest of the paper, we assume that the mission
graph is given. We will use the terms task, activity,
and node interchangeably. A task will be denoted by
t
i
. Nonetheless, a task t
i
differs from an action a: an
action consists of a task and a start time.
Each task t
i
is characterized by its time window
and by the uncertainty about its duration δ
i
(t
i
) and
about its resource consumption δ
r
(t
i
). When it is un-
ambiguous, we will suppress the activity argument t
i
for conciseness.
Temporal window of Tasks Each task is assigned
a temporal window [EST, LET] during which it must
be executed. The execution of the activity (both start
and end times) must be included in this interval for
the task to succeed.
Uncertain execution time The uncertainty on du-
rations has been considered in several approaches de-
veloped in (Mouaddib and Zilberstein, 1998; Zilber-
stein and Mouaddib, 1999; Cardon et al., 2001). All
OPTIMAL PLANNING FOR AUTONOMOUS AGENTS UNDER TIME AND RESOURCE UNCERTAINTY
183

of them ignore the uncertainty on the start time. We
show in this paper how extensions can be considered,
taking different temporal constraints into account.
Uncertain resource consumption The consump-
tion of resources (energy, memory, etc ...) is uncer-
tain. As the agent has limited initial resources, it must
consider resource constraints.
We assume that resource consumption and execu-
tion time are dependent. The representation adopted
for these distributions is discrete.
Definition 1 Let SP be a set of pairs (∆t, ∆r). We
denote P ((∆t, ∆r)) the probability the task con-
sumes ∆r resources and ∆t units of time.
If resource consumption and execution time are in-
dependent, we simply have :
P ((∆t, ∆r)) = P (∆t).P (∆r).
Overview In order to formalize our problem as a
MDP, we need further information about the tasks. In
fact, we must know the possible execution intervals of
each task and their probabilities. Once these informa-
tion are known, the MDP can be defined and solved.
Our approach can be divided into several steps.
It first propagates the temporal constraints and com-
putes the set of possible time intervals for each task,
computing theire probabilities. The MDP is then con-
structed using these information and solved by the
Policy Iteration algorithm (Howard, 1960).
3 TEMPORAL INTERVAL AND
PROBABILITY PROPAGATION
The decision process bases its decision on the remain-
ing resources, the latest executed task and the execu-
tion interval of this task.
Many possible execution intervals exist for each
task. In order to explore the whole state space, we
need to know the set of possible execution intervals.
Therefore, we developed an algorithm that computes
all the possible time intervals from the mission graph,
weighted by a probability. This probabilistic weight
allows us to know the probability that an activity will
be executed during a given interval of time.
The set of possible start times of a task is a subset of
{EST, EST +1, . . . , LET −min δ
i
} (EST : Earliest
Start Time, LET : Latest End Time). We denote the
Latest Start Time as LST = LET − min δ
i
where
min δ
i
is the minimum duration of the task.
To start the execution of a task t
i
, the agent must
have executed one of the predecessors of t
i
. The start
time of t
i
therefore depends on the end time of its
predecessor. We can compute off-line all the possi-
ble end times of an activity’s predecessors and conse-
quently compute the possible start times of the activ-
ity. The algorithm is similar to the one described in
(Bresina and Washington, 2000). The possible exe-
cution intervals I are determined by a simple forward
propagation of temporal constraints in the graph. This
propagation organizes the graph into levels such that:
l
0
is the root of the graph, l
1
contains all nodes that
are constrained only by the root node, . . ., l
i
contains
all the successor nodes of the nodes in level l
i−1
. For
each node in a given level l
i
, we compute all its pos-
sible execution intervals from its predecessors.
• level l
0
: the start time and the end times of the root
node (the first task of the mission) are computed as
follows:
– start time: st(root) = EST (root)
– end times: ET (root) = {st(root) +
δ
i
(root), ∀δ
i
(root)}
Possible execution intervals of the root are given
by I = [st(root), et(root)] with et(root) ∈
ET (root). Note that there is potentially a non-zero
probability that some end times violate the deadline
LET .
• level l
i
: for each node in level l
i
, the possible start
times are the times at which the predecessor activ-
ities can finish. We first compute all the possible
start times, and then we eliminate the start times
that do not respect the constraints of earliest start
time: st < EST , and latest start time: st > LST .
For each possible start time, we compute the pos-
sible end times, accounting for the possible dura-
tions of the node. Note that potentially st(node) +
δ
i
(node) > LET (node)
Many classical algorithms exist in literature, like
PERT, but most of them don’t deal with uncertainties
on execution time.
As explained in the next section, we must com-
pute the possible execution intervals to define the state
space. Probabilities on these intervals must also be
known to compute the transition probabilities.
The probability of an execution interval P
w
de-
pends on its start time and on the probability of its
duration P
c
.
A task cannot start before its predecessor finishes.
Therefore, the probability on the start time depends
on the predecessor’ end time. We will consider a task
t
i
. P
w
(I|et(I
′
)) denotes the probability that t
i
is ex-
ecuted in the interval I when its predecessor finishes
at et(I
′
). This value measures the probability that an
activity starts at st(I) and ends at et(I).
In order to respect temporal constraints, an agent
executes the next task as soon as possible: if it de-
lays the execution of the next task, it will increase the
probability of violating the deadline with no expected
ICINCO 2006 - ROBOTICS AND AUTOMATION
184

Send
data
Snap
the target
Move to
the target
Atmospheric
measurement
Atmospheric
measurement
Send
data
Snap
the target
Move to
the target
Figure 2: Relationship between the original graph structure
and the MDP state space.
gain. If st(I) ≥ et(I
′
) and there is no possible start
time for t
i
in ]et(I
′
), st(I)[, the agent will start the
execution at st(I).
The probability P
w
(I|et(I
′
)) of an execution inter-
val I is defined as follows:
• If st(I) is the first possible start time such that
st(I) ≥ et(I
′
): P
w
(I|et(I
′
)) = P
c
(et(I) − st(I))
• Otherwise: P
w
(I|et(I
′
)) = 0
These probabilities are computed off-line during
the forward propagation of temporal constraints. By
propagating temporal constraints and their probabili-
ties through the mission graph, the algorithm allows
for developing the entire state space.
4 A DECISION MODEL: MDP
As mentioned above, we model this problem with a
Markov Decision Process.
Definition 2 A Markov Decision Process (MDP) is
defined by a tuple < S, A, P, R >:
• S is a finite set of states s
• A is a finite set of stochastic actions a
• P : S × A × S is a Markovian transition function
that gives the probability the agent moves to a state
s when it executes action a from s
′
.
• R is a reward function
To solve our problem, we need to define the state
space, the action set, the transition function and the
reward function of our model. These components can
be deduced from the initial mission graph. Figure 2
gives a representation of the relationship between the
original graph structure, the state space and the transi-
tions of the MDP. The left part of the figure stands for
the mission graph. The right part represents the state
space of the MDP and its transitions. Each box groups
the states associated with a task t
i
. Each node stands
for a state and edges represent the transitions between
the states.Some nodes have no successor: they are ter-
minal states.
State Space At each decision step, the agent must
decide for the execution of a task. The success of this
execution depends on the temporal constraints and the
available resources. If temporal constraints are not
respected or if the agent lacks resources, the execu-
tion of the task fails and the agent moves to a fail-
ure state. Otherwise, the execution succeeds and the
agent moves to a success state. The decision relies
on three parameters: the latest executed task t
i
, the
available resources r, and the interval of time I dur-
ing which task t
i
has been executed. A state is there-
fore defined by a triplet [t
i
, r, I]. States are fully ob-
servable since the temporal intervals are determined
off-line and the resource consumption is observed by
the agent as an environment feedback.
For each task, we develop a set of states by com-
bining the execution intervals and the remaining re-
sources. Possible resource rates are computed by
propagating resource consumptions through the mis-
sion graph. The consequence of representing all the
intervals and resource levels is that the state space be-
comes fully observable. The decision process can per-
form its action selection using the Bellman equation
defined below.
Action Space From each non terminal state, the
agent should choose which task to execute and when
to start its execution. Note that the decision depends
only on the current state and thus this process has the
Markov property. The set of actions a = E
i
(st) to
perform consists of Executing task t
i
at time st, where
t
i
is a successor of the latest executed task. This ac-
tion a is probabilistic since the duration and resource
consumption of the task are uncertain. Standard MDPs
used to represent one time unit actions. Our approach
extends this model and allows for representing vari-
ous possible durations for each action.
Transition model When the agent starts executing
an action from a state [t
i
, r, I], it can move to vari-
ous states. If temporal and resource constraints are
respected, the execution succeeds. If the agent lacks
resources, starts too late or violates the deadline, it
fails. Failure states are considered as terminal states.
It is straightforward to adapt our system to non termi-
nal failure states. States associated with the last task
of the mission are also terminal states.
Four kinds of transitions have to be considered:
• Successful Transition: The action allows the agent
to move to [t
i+1
, r
′
, I
′
] where task t
i+1
has been
achieved during the interval I
′
, respecting the EST
and LET of this task, and r
′
are the remaining re-
sources. The probability P
SU C
of moving to the
state [t
i+1
, r
′
, I
′
] is :
P
SU C
=
X
(∆t,∆r)∈SP |∆r≤r and st(I
′
)+∆t=et(I
′
)
P ((∆r, ∆t))
OPTIMAL PLANNING FOR AUTONOMOUS AGENTS UNDER TIME AND RESOURCE UNCERTAINTY
185

• Too late start time (TLST) Transition: The agent
starts too late (after LST). In such a case, the agent
moves to a failure state [f ailure, r, [st, +∞]] (in
fact, the resource and interval arguments are unim-
portant since the state is terminal). The transition
probability P
T LST
is defined as:
P
T LST
= P r(st > LST ).
• Deadline met Transition: The agent starts to ex-
ecute the task at time st but the duration δ
i
is so
long that the deadline is met. This transition moves
to the state [f ailure, r, [st, +∞]]. The probability
P
DM T
of moving to this state is: P
DM T
=
P r(st ≤ LST ) ·
X
(∆t,∆r)∈SP |∆r≤r and LET −∆t<st≤LST
P ((∆t, ∆r))
• Insufficient resource Transition: The execution re-
quires more resources than available. The agent
moves to a state [f ailure, 0, [st, +∞]]. The prob-
ability P
IRT
of moving to this state is:
P
IRT
=
P
(∆t,∆r)∈SP|∆r>r
P ((∆t, ∆r))
Reward function Each time the agent finishes to
execute a task within temporal, precedence and re-
source constraints, it obtains a reward which depends
on the executed task. R
i
is the reward the agent ob-
tains when it has accomplished the task t
i
.
As the number of tasks and start times are finite, the
horizon of the MDP is finite. Since time is considered
in each state, the MDP have no loop.
MDP resolution Once the MDP is defined, it can
be solved optimally. To compute an optimal policy
for the agent, we use dynamic programing and Bell-
man principle of optimality. A policy is a mapping
from states to actions: for each state it dictates which
action to execute. It allows the agent to execute its
tasks autonomously. The value of each state relies on
the immediate gain (reward) and the expected value
that takes into account the various possible transi-
tions. Each state is valued as follows:
V ([t
i
, r, I]) = R
i
+ max
E
k
(st≥et(I)),k=successor(t
i
)
(V
′
)
where V
′
is the expected value of future tasks. We
decompose V
′
as V
′
= V
SU C
+ V
F AIL
such that:
• Expected Value of successful transition:
V
SU C
=
X
(∆t,∆r)∈SP |∆r≤r and st(I
′
)+∆t=et(I
′
)
P ((∆r, ∆t).V ([t
i+1
, r−∆
r
, I
′
])
This value is used when the task starts and finishes
with success: there is enough resources and I
′
is the
execution interval of the next activity.
• Expected Value of failure transition: Otherwise,
the execution fails because the agent lacks resources
or temporal constraints are violated.
V
F AIL
= P
F AIL
· V ([failure, ∗, ∗])
with P
F AIL
= P
T LST
+P
DM T
+P
IRT
= 1−P
SU C
.
Note that resources and intervals are unimportant.
The policy π of a state [t
i
, r, I] is given by:
π([t
i
, r, I]) = R
i
+ arg max
E
k
(st≥et(I)),k=successor(a
i
)
(V
′
)
Optimality The MDP is easily solved using the
standard dynamic programming algorithm policy it-
eration. Therefore, the obtained policy is optimal.
Precedence constraints allows for ordering the policy
revision: the tasks are considered from the leaves to
the node. Thus, there is no need to iterate the algo-
rithm since there is no loop.
5 RELATED WORK
There has been considerable work in planning un-
der uncertainty that leads to two categories of plan-
ners: conformant planners and contingent planners.
These planners are characterized by 2 important cri-
teria: representation of uncertainty and observability.
The first criterion, the uncertainty representation, has
been addressed in two ways in many planners using
disjunction or probability while the second criterion is
composed of Non-observability (NO), partial observ-
ability (PO) or a full observability (FO) of planners.
A survey on all classes of planners can be found in
Blythe (Blythe, 1999) and Boutilier (Boutilier et al.,
1999) where details are given on NO, PO, or FO
disjunctive planners and on NO, PO or FO proba-
bilistic planners. Let us just recall some of those
planners: C-PLAN NO-disjunctive planner, Puccini
PO-disjunctive planner, Warplan FO-disjunctive plan-
ner, Buridan NO probabilistic planner, POMDP, C-
MAXPLAN PO probabilistic planners and JIC, MDP
FO probabilistic planners. In this section we focus
on why those planners are unsuitable for our concern
and why our work is a contribution to overcome those
limits. These planners encounter some difficulties in
our domain of interest:
• Model of time: the existing planners do not sup-
port explicit time constraints nor complex temporal
dependencies.
• Model of actions: the existing planners assume
that actions are instantaneous.
• Scalability: the existing planners do not scale to
large problems. For rover operations, a daily plan can
involve on the order of a hundred operations, many of
which having uncertain outcomes.
The approach we present in this paper meets the re-
quirements for a rich model of time and actions and
for scalability. It complements the work initiated in
(Bresina and Washington, 2000) by using a similar
model of time and utility distribution and by using
ICINCO 2006 - ROBOTICS AND AUTOMATION
186

a decision-theoretic approach. The advantage of us-
ing such an approach is to achieve optimality. An-
other contribution consists of handling uncertainty on
resource consumption combined with uncertainty on
execution time.
In the MDP we present, actions are not instanta-
neous as in the previous planners and can deal with
complex time constraints such as a temporal window
of execution and temporal precedence constraints. We
also show that our approach can solve large problems
with a hundred operations, many of which are uncer-
tain. Another requirement mentioned for the rover
applications is concurrent actions. This problem is
under development, taking advantage of some multi-
agent concepts : as soon as the rover needs to execute
two actions, we consider those actions are concurrent
agents. This new line of research allows for bridg-
ing the gap between the multiagent systems and the
distributed MDP.
6 CONCLUSION AND FUTURE
WORK
In this paper we presented an MDP planning technique
that allows for a plan where operations have complex
dependencies, time and resource constraints. The op-
erations are organized in an acyclic graph where each
operation has a temporal window during which it can
be executed and an uncertain resource consumption
and execution time. This approach is based on an
MDP using a rich model of time and resources with
dependencies between tasks. This technique allows
us to deal with the variable duration of actions. We
presented experimental results showing that our ap-
proach can scale to large robotic problems (a hundred
of operations). Our approach also overcomes some of
the limitations described in (Bresina et al., 2002). In-
deed, our model is able to handle more complex time
constraints and uncertainty on durations and resource
consumptions. Moreover, as required in (Bresina
et al., 2002), our system can consider plans of more
than a hundred tasks.
In this paper, we have focused on planetary rover
applications. Nonetheless, our approach is not re-
stricted to space applications. It can be applied to
any scenario formalized by an acyclic graph with tem-
poral constraints. However, this approach needs to
be extended to other requirements such as continuous
variables. In our current version of the approach we
use a discrete representation of time and resources.
We are specially interested in finding tradeoffs be-
tween the scalability, execution errors and discretiza-
tion. The other extension we are developing consists
of dealing with multiple agents using a distributed
MDP. Future work may concern the construction of
the graphs that we consider as given in this paper.
REFERENCES
Blythe, J. (1999). Planning under uncertainty in Dynamic
domains. PhD, Carnegie Mellon University.
Boutilier, C., Dean, T., and Hanks, S. (1999). Decision-
theoretic planning: Structural asumptions and com-
putational leverage. Journal of Articicial Intelligence
Research, 1:1–93.
Bresina, J., Dearden, R., Meuleau, N., Ramkrishnan, S.,
Smith, D., and Washington, R. (2002). Planning un-
der continuous time and resource uncertainty: A chal-
lenge for ai. In Proceedings of the 18th Annual Con-
ference on Uncertainty in Artificial Intelligence (UAI-
02), pages 77–84, San Francisco, CA. Morgan Kauf-
mann Publishers.
Bresina, J. and Washington, R. (2000). Expected utility dis-
tributions for flexible contingent execution. In AAAI
Workshop on Representation issues for Real World
Planning system.
Cardon, S., Mouaddib, A., Zilberstein, S., and Washing-
ton, R. (2001). Adaptive control of acyclic progressive
processing task structures. In IJCAI, pages 701–706.
Estlin, T. A., Gray, A., Mann, T., Rabideau, G., Castano,
R., Chien, S., and Mjolsness, E. (1999). An inte-
grated system for multi-rover scientific exploration. In
AAAI/IAAI, pages 613–620.
Howard, R. A. (1960). Dynamic Programming and Markov
Processes. MIT Press.
Morris, P., Muscettola, N., and Vidal, T. (2001). Dynamic
control of plans with temporal uncertainty. In IJCAI,
pages 494–502.
Mouaddib, A.-I. and Zilberstein, S. (1998). Optimal
scheduling for dynamic progressive processing. In
ECAI-98, pages 499–503.
Sutton, R. S., Precup, D., and Singh, S. P. (1999). Between
MDPs and semi-MDPs: A framework for temporal
abstraction in reinforcement learning. volume 112,
pages 181–211.
Tsamardinos, I., Pollack, M., and Ramakrishnan, S. (2003).
Assessing the probability of legal execution of plans
with temporal uncertainty. In ICAPS Workshop on
Planning under uncertainty and Incomplete informa-
tion.
Vidal, T. and Ghallab, M. (1996). Dealing with uncertain
durations in temporal constraints networks dedicated
to planning. In 12
th
ECAI, pages 48–54.
Zilberstein, S. and Mouaddib, A.-I. (1999). Reactive con-
trol for dynamic progressive processing. In IJCAI-99,
pages 1269–1273.
OPTIMAL PLANNING FOR AUTONOMOUS AGENTS UNDER TIME AND RESOURCE UNCERTAINTY
187
