
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER
Terrence Mason
Iowa Database and Emerging Applications Laboratory, Computer Science
University of Iowa
Ramon Lawrence
Iowa Database and Emerging Applications Laboratory, Computer Science
University of Iowa
Keywords:
integration, database, schema, metadata, annotation, evolution, dynamic, JDBC, conceptual, embedded.
Abstract:
Current integration techniques are unsuitable for large-scale integrations involving numerous heterogeneous
data sources. Existing methods either require the user to know the semantics of all data sources or they
impose a static global view that is not tolerant of schema evolution. These assumptions are not valid in
many environments. We present a different approach to integration based on annotation. The contribution is
the elimination of the bottleneck of global view construction by moving the complicated task of identifying
semantics to local annotators instead of global integrators. This allows the integration to be more automated,
scaleable, and rapidly deployable. The algorithms are packaged in an embedded database engine contained
in a JDBC driver capable of dynamically integrating data sources. Experimental results demonstrate that the
Unity JDBC driver efficiently integrates data located in separate data sources with minimal overhead.
1 INTRODUCTION
Large-scale integration involving numerous heteroge-
neous databases is limited by imposing a static global
view or requiring users to know the semantics of the
integrated data sources. A robust integration system
will dynamically update the global schema represent-
ing the integrated data sources. Our approach pushes
the most challenging task of integration, identifying
semantics, to local annotators instead of global inte-
grators. The system automates the tasks of matching
and resolving structural conflicts. Integrators are only
responsible for annotating local data with the neces-
sary context so that it may be integrated into the over-
all system. Annotation allows related concepts to be
identified and referenced using accepted terminology.
The advantage of matching on schema annotations
rather than the schemas themselves is that the over-
head of human interaction is limited to gathering
semantics at each database individually rather than
identifying relationships during the matching process.
This is important as the annotation only needs to be
performed once per database, as opposed to having
human involvement during every match operation.
This reduces the requirement that global integrators
fully understand the semantics of every schema.
The success of the integration rests on being able to
construct standardized annotation that can be matched
across systems. A common complaint against such an
approach is that users will not adopt standards. Al-
though this may be the case in some environments, it
is not universally true. There is an increasing trend
in organizations to standardize common terms, fields,
and database elements, especially in the medical and
scientific domains. For example, the National Can-
cer Institute Center for Bioinformatics (NCICB)
1
has
developed a standardized ontology called Enterprise
Vocabulary Services (EVS) (Covitz et al., 2003) for
common terms in the cancer domain. NCICB has also
created a Cancer Data Standards Repository (caDSR)
to standardize the data elements used for cancer re-
search. As part of a national initiative to build a grid
of cancer centers, individual centers must conform
their data to be compliant with Common Data Ele-
ments (CDEs) and EVS. This compliance is achieved
by annotating their data sources with the accepted ter-
minology. Thus, it is not uncommon to require a stan-
dard for participants who wish to share and integrate
their data. Once local sources are annotated to con-
form to the standards, the global-level matching is
considerably simplified because concepts will match
across databases if they agree on the particular stan-
dardized term or data element.
1
http://ncicb.nci.nih.gov
326
Mason T. and Lawrence R. (2005).
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER.
In Proceedings of the Seventh International Conference on Enterprise Information Systems , pages 326-333
DOI: 10.5220/0002552103260333
Copyright
c
SciTePress

Unity enables the dynamic integration of large
numbers of data sources that are annotated accord-
ing to a reference vocabulary. The architecture is ca-
pable of handling large-scale integrations in evolving
environments, where the specific databases participat-
ing in the federation change frequently and their local
schemas evolve over time. In addition, the driver’s
database engine integrates distributed data sources
without requiring middleware or database server sup-
port and allows programmers simplified access to in-
tegration algorithms.
A lightweight integration system is implemented
inside a JDBC driver to provide a standard interface
for querying heterogeneous databases. Integration
is supported with an embedded database engine that
joins data located in multiple data sources into a sin-
gle result. The JDBC standard allows the execution
of queries in a general programming environment by
providing library routines which interface with the
database. In particular, JDBC has a rich collection
of routines which make the interface simple and intu-
itive. The result is increased portability and a cleaner
client-server relationship. For an integration system
in an evolving environment to succeed, it will require
an automatic and scalable approach with a standard
interface to access the data.
The challenge of integration is to build a platform-
independent system that supports automated con-
struction of an integrated view, handles schema evo-
lution, and allows the dynamic addition and deletion
of sources. Our contribution is an integration archi-
tecture that has several unique features:
• A method for annotating schemas using reference
ontologies and automatically matching annotated
schemas to produce a global view.
• A simple conceptual query language that reduces
the complexity often found in SQL queries.
• The system automatically determines the necessary
joins and relations in each data source and across
data sources.
• A system for tracking data provenance and detect-
ing inconsistent data across databases.
• Updates the global view automatically to handle
addition or deletion of data sources.
• Algorithms implemented in the standard JDBC in-
terface.
The organization of this paper is as follows. Sec-
tion 2 reviews existing integration systems. In Sec-
tion 3, the JDBC driver implementation and its archi-
tecture is described. Section 4 details performance
experiments that show the JDBC implementation has
minimal overhead for integrating data sources. The
paper closes with future work and conclusions.
2 PREVIOUS WORK
Several data integration prototypes (Goh et al., 1999;
Kirk et al., 1995; Li et al., 1998) have been developed.
In the literature, there are two basic types of data inte-
gration systems (Halevy, 2001; Ullman, 1997): global
as view (GAV) systems and local as view (LAV)
systems. The difference between the two types is
how the mappings are expressed between the global
view and the source. Although schema matching
systems (Rahm and Bernstein, 2001) semi-automate
mapping discovery between the global view and the
sources, they have proven less successful in construct-
ing the global view itself. While progress contin-
ues to be made using a reference ontology (Dragut
and Lawrence, 2004), global view construction and
its evolution remains an open issue.
Data integration systems (Lenzerini, 2002) require
a global view to be constructed before local sources
are integrated into the federation. The bottleneck
in the integration process is the construction of the
global schema, as schemas do not contain enough in-
formation to allow conflicts between data representa-
tions to be automatically identified and resolved. Cur-
rent approaches to integration (Lenzerini, 2002) as-
sume static schemas, data sources, and global level
knowledge to build the integrated view. In prac-
tice, integrators have limited knowledge of the data
sources. Systems must be integrated quickly, and the
scale of integration makes defining global relations
challenging.
Many commercial systems are based on federations
(Sheth and Larson, 1990) such as federation in DB2
(Haas et al., 2002). These systems allow the shar-
ing of schemas across databases but require users to
perform the integration through query formulation.
Federation is not desirable for large-scale integrations
because of the complexity in writing queries. Such
queries are susceptible to evolution and require the
user to understand the semantics of all schemas.
Using an ontology for integration has been used
previously (Collet et al., 1991; Decker et al., 1998).
These systems require sources to completely commit
to a global ontology and manually map all of their
data to the ontology. Since ontologies have more
powerful modeling constructs, their construction is
more challenging, and it becomes an issue if the lo-
cal sources will commit to using such an ontology. It
remains challenging to construct and refine a global
ontology. Unity does not require complete confor-
mance to an ontology, but only a sharing of standard
terms for common elements. No previous integration
system has been deployed in a standard API such as
JDBC.
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER
327
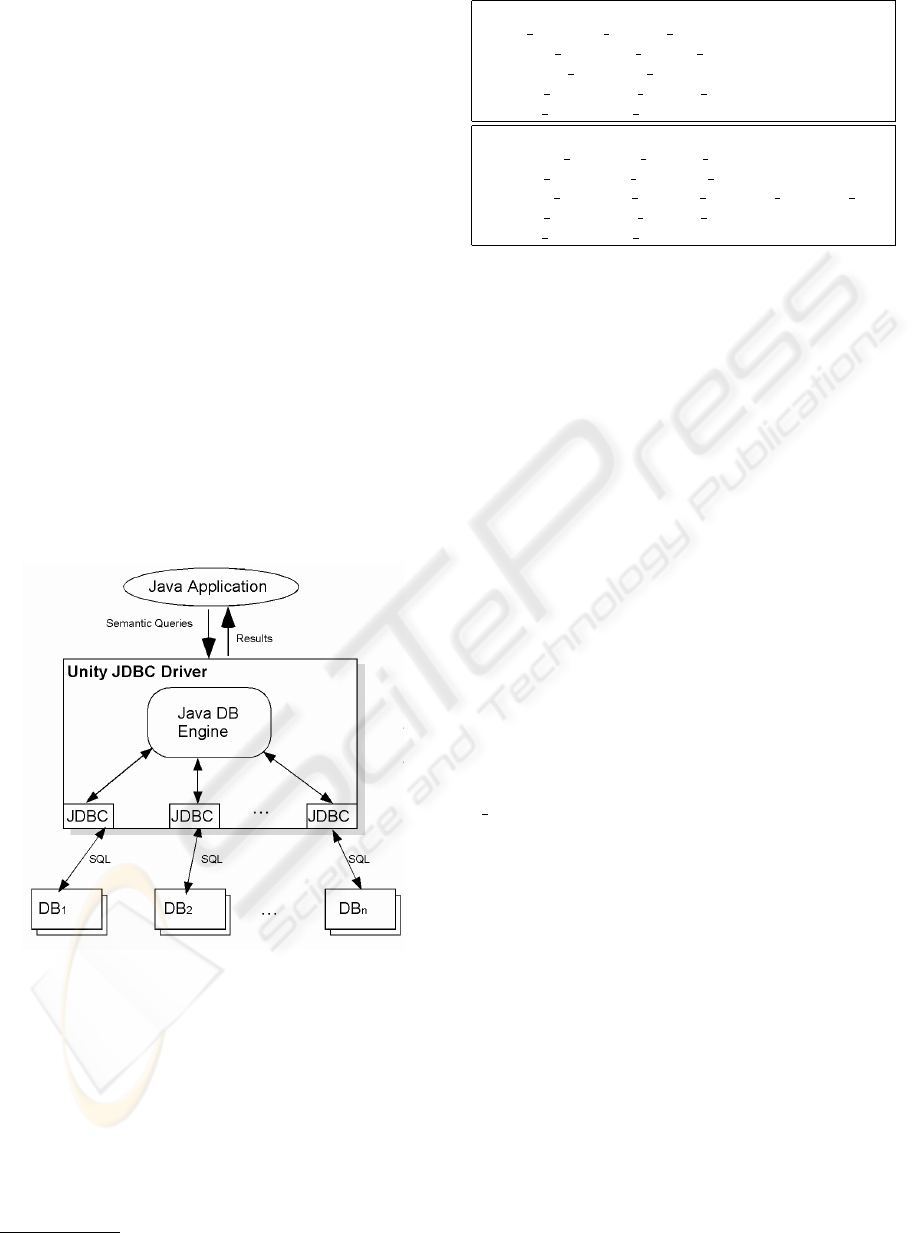
3 INTEGRATION
ARCHITECTURE
The unique features and algorithms of Unity are im-
plemented in a JDBC driver allowing programs to
transparently query one or more databases. The abil-
ity to integrate databases without additional software
makes it easier and faster to integrate systems in dy-
namic environments. The driver isolates the com-
plexities of integration from the application program-
mer by automatically building an integrated view and
mapping conceptual queries to SQL. While the sys-
tem is deployed in the Unity JDBC driver (Figure 1),
the algorithms are not specific to a JDBC implemen-
tation and can be deployed using other technologies.
The TPC-H
2
schema is partitioned into two schemas
(Figure 2) to provide an example integration scenario
for this paper. A program invoking standard JDBC
method calls will be used to describe the Unity JDBC
Driver system architecture and integration algorithms.
The functions are exactly the same as those in a single
source JDBC driver. The difference is that the Unity
driver allows the programmer to transparently access
multiple sources instead of just one.
Figure 1: JDBC Integration Driver Architecture
3.1 Building the Global Schema
Given the importance of names and text descriptions
in schema matching, it is valuable for schemas to
be annotated before they are integrated. Our sys-
tem uses annotation to build the global view in a
bottom-up fashion. A data source administrator an-
notates a schema with meaningful names (possibly
2
http://www.tpc.org/tpch
Part Database
part(p partkey, p name, p mfgr)
supplier(s suppkey, s name, s nationkey)
partsupp(ps partkey,ps suppkey)
nation(n nationkey, n name, n regionkey)
region(r regionkey, r name)
Order Database
customer(c custkey, c name, c nationkey)
orders(o orderkey, o custkey, o orderdate)
lineitem(l orderkey,l partkey,l suppkey,l linenum,l qty)
nation(n nationkey, n name, n regionkey)
region(r regionkey, r name)
Figure 2: Database Schemas
using an ontology such as EVS) and exports the anno-
tated schema in an XML document. The JDBC driver
loads the individual annotations, matches names in
the annotations to produce an integrated view, and
then identifies global keys for use in joins across data-
bases.
In the cancer domain (discussed in Section 1),
matching on annotations is trivial as each common
data element has a unique id and name. In other do-
mains, the matching may be more complex, especially
if standard conformance is loosely enforced. It is im-
portant to emphasize that the annotation, not the local
or global schemas, is built according to an accepted
standard. Unlike ontology-based systems, sources do
not commit to a standard ontology/schema, but agree
to annotate their existing schemas in a standardized
fashion. The global schema is built by matching an-
notations in a bottom-up fashion and will contain only
the concepts present in the sources.
Figure 3 shows a partial annotation of the Part re-
lation in the Part database of Figure 2. The field
p partkey is annotated as Part.Id in the global schema.
Two fields match if they have the same semantic
name. This provides the mechanism for matching
fields with the same domains across multiple data-
bases. The primary and foreign keys are used to
identify potential joins. The annotation provides the
global attribute names for the query language. This
flexible, scaleable, and unobtrusive approach suc-
ceeds as a site must annotate only local schemas so
that they can be integrated with other systems.
The global schema produced by matching the Part
database with the Order database is shown in Figure
4. The global schema is a universal relation of all
attributes in the underlying schemas and is produced
by taking the attributes of each schema and merging
them into the universal view. Since attribute domains
are uniquely identified by the annotation, this merge
process is completely automatic.
Mismatches are possible at the global level if the
annotators assign an incorrect term to their attribute.
Note that we expect there to be some errors during the
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
328

<TABLE>
<semanticTableName>Part</semanticTableName>
<tableName>part</tableName>
<FIELD>
<semanticFieldName>Part.Name</semanticFieldName>
<fieldName>p
name</fieldName>
<dataTypeName>varchar</dataTypeName>
<fieldSize>55</fieldSize>
</FIELD>
<FIELD>
<semanticFieldName>Part.Id</semanticFieldName>
<fieldName>p
partkey</fieldName>
<dataTypeName>int</dataTypeName>
<fieldSize>10</fieldSize>
</FIELD>
<PRIMARYKEY>
<keyScope>5</keyScope>
<keyScopeName>Organization</keyScopeName>
<FIELDS>
<fieldName>p
partkey</fieldName>
</FIELDS>
</PRIMARYKEY>
</TABLE>
Figure 3: Partial Annotation of Part Table
automatic matching because annotations may not be
perfect. The global view is iteratively refined to cor-
rect such errors. However, the system is resistant to
such errors as either a match goes undiscovered (cre-
ates two attributes in the global view instead of one)
or a single attribute in the global view is used for two
or more distinct attribute domains. When these errors
are detected at the global level, they are resolved by
modifying the local annotations. The result of merg-
ing annotations is independent of the order that they
are merged. Note that the M-N relation PartSupp is
abstracted from the global view as it will only be used
during the local inference process.
Part.Id, Part.Name, Part.Manufacturer
Supplier.Id, Supplier.Name, Supplier.Nation.Id
Order.Id, Order.Customer.Id, Order.Date
LineItem.Linenumber, LineItem.Order.Id
LineItem.Quantity, LineItem.Part.Id, LineItem.Supplier.Id
Customer.Id, Customer.Name, Customer.Nation.Id
Nation.Id, Nation.Name, Nation.Region.Id
Region.Id, Region.Name
Figure 4: Global Schema
Note that the Unity JDBC driver could be used
even when no annotation is performed and conceptual
querying is not used. In this case, all relations from
all databases are imported into the global view but
not matched. Integration occurs when users explic-
itly state the joins in their queries. Thus, at the lowest
level, the JDBC driver functions as a standard fed-
erated system allowing distributed access to the data
sources. However, its true benefit is abstracting away
the challenges of building joins and matching schema
constructs manually.
3.2 Embedded Integration Engine
A lightweight database engine is developed and em-
bedded in the JDBC driver implementation. It is re-
quired to parse the conceptual query, build a logical
query plan, and then execute the query plan. The op-
timizer selects the join method and a join ordering
to connect data across the data sources. The execu-
tion engine is capable of handling data sets larger than
main memory by filtering and joining them efficiently
using secondary storage at the client.
3.2.1 Making Connections
In the sample application (Figure 5), the URL speci-
fied in Line 1 references the sources.xml file con-
taining information on each data source to be inte-
grated. In Line 6, after registering the driver, the first
task is to specify which sources to use. This is done
using a sources XML file that contains source infor-
mation such as the server, connection protocol, and
annotation. This information is used by the Unity
JDBC driver to connect to individual sources. The
programmer may dynamically change which sources
are included in the integration. When a connection
is made, two things happen. First, the Unity JDBC
driver uses the configuration information to make a
connection to each data source specified. Second, the
integration algorithm is run to match and merge the
schema annotations in the XML files. The output af-
ter making a connection is an integrated, global view.
3.2.2 Conceptual Querying
Although querying is possible through SQL in this
model, it requires complete knowledge of the rela-
tionships within and between the data sources to spec-
ify joins. A simpler conceptual query language is de-
veloped that allows users to query without specifying
joins, as most users will not know all the details of an
integrated schema. The query language is an attribute
only version of SQL, where the SELECT clause con-
tains the concepts to be projected in the final results
and the optional WHERE clause specifies selection
criteria for the query. By giving each field a mean-
ingful semantic name, users can query on the name
in the annotation instead of the explicit relation and
field names of the individual data sources. Notice the
absence of the FROM clause, as well as, no explicit
specification of joins. The integration system will au-
tomatically identify these elements from the attributes
specified in the conceptual query.
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER
329

The concepts in the query (semantic names) map
to fields in the relations. In Lines 8, 9 and 10 of
the example program, the conceptual query (contain-
ing only attributes) is passed to the driver using the
standard JDBC method. In this example, the user has
queried on: Part.Name, LineItem.Quantity, and Cus-
tomer.Name. These are mapped to their locations in
the databases: Part.Name → part.p
name (Part DB),
LineItem.Quantity → lineitem.l
qty (Order DB), Cus-
tomer.Name → customer.c
name (Order DB). Users
query on the annotation (attributes of the universal
view), and the system performs query inference to
find the required joins.
The conceptual query is parsed inside the Unity
driver and converted to a parse tree using a JavaCC
3
based parser. The parse tree identifies all of the at-
tributes and their relations in the local data sources
for use in the generation of the integrated result.
import java.sql.*;
public class JDBCApplication
{
public static void main(String[] args)
{
String url = “jdbc:unity://sources.xml”; (1)
Connection con; (2)
// Load UnityDriver class
try { Class.forName(“unity.jdbc.UnityDriver”); } (3)
catch (java.lang.ClassNotFoundException e) { System.exit(1); } (4)
try { // Initiate connection (5)
con = DriverManager.getConnection(url); (6)
Statement stmt = con.createStatement(); (7)
ResultSet rst = stmt.executeQuery(“SELECT Part.Name, (8)
LineItem.Quantity, Customer.Name (9)
WHERE Customer.Name=’Customer
25’”); (10)
System.out.println(“Part , Quantity, Customer”); (11)
while (rst.next()) (12)
System.out.println(rst.getString(“Part.Name”) (13)
+“,”+rst.getString(“LineItem.Quantity”) (14)
+“,”+rst.getString(“Customer.Name”)); (15)
con.close(); (16)
} (17)
catch (SQLException ex) { System.exit(1); } (18)
}
}
Figure 5: Sample JDBC Application
3.2.3 Building Subqueries
The query’s parse tree is translated into an execution
tree consisting of operators such as select, project,
join, and sort. The joins required to relate the at-
tributes and complete the query must be identified.
There are two levels of query inference required for
querying a global schema: local and global. Lo-
3
https://javacc.dev.java.net
cal query inference determines the joins within a sin-
gle data source. The conceptual query specifying at-
tributes of the global schema is mapped to attributes
and relations in each data source. A join graph
G=(V, E) provides a directed graph representation of
a relational schema, where each node in V represents
a relation and each edge of E represents a foreign
key constraint between two relations. Inferring the re-
quired joins reduces to the problem of determining the
minimal edge set to connect the specified nodes (re-
lations) in the graph. The minimal set of joins repre-
sents the strongest relationship between the attributes
(Goldman et al., 1998). The inference algorithm uses
a shortest-path approximation of the Steiner tree algo-
rithm (Wald and Sorenson, 1984). The result of local
inference is a join tree for each data source.
Since there is only one attribute/relation required
from the Part database, it is straightforward to gener-
ate the join tree of one node. However, in the Or-
der database, fields from the relations customer to
lineitem are requested, but these relations do not have
a direct connection between them. Query inference
determines the shortest path which results in a join
path from lineitem to customer through the orders re-
lation. The join trees are used to build the execution
trees by adding in any additional join operators re-
quired for the query. The selection operator must be
added to the execution tree of the subquery for the
Order database to select only Customer
25 from
the customer relation. The operator execution tree for
the discussed subqueries are shown in Figure 6. The
subquery execution trees are converted into SQL sub-
queries to be executed at each local data source by
inserting the nodes in the FROM clause and the joins
in the WHERE clause. In addition, the selection crite-
ria is included in the WHERE clause. Note that both
subqueries include the additional attribute partkey,
which will be used to integrate the subqueries. The
resulting subqueries are shown below:
Subquery 1: Order Database
SELECT l
qty, c name, l partkey
FROM lineitem, customer, order
WHERE o
custkey=c custkey and l orderkey=o orderkey
c
name=’Customer 25’
Subquery 2: Part Database
SELECT p
name, p partkey FROM part
3.2.4 Integrating Results
Once local inference is complete and the subqueries
are created, the database engine determines how the
data extracted from each source can be related. To
combine the subquery results, global inference deter-
mines the joins across data sources by identifying and
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
330
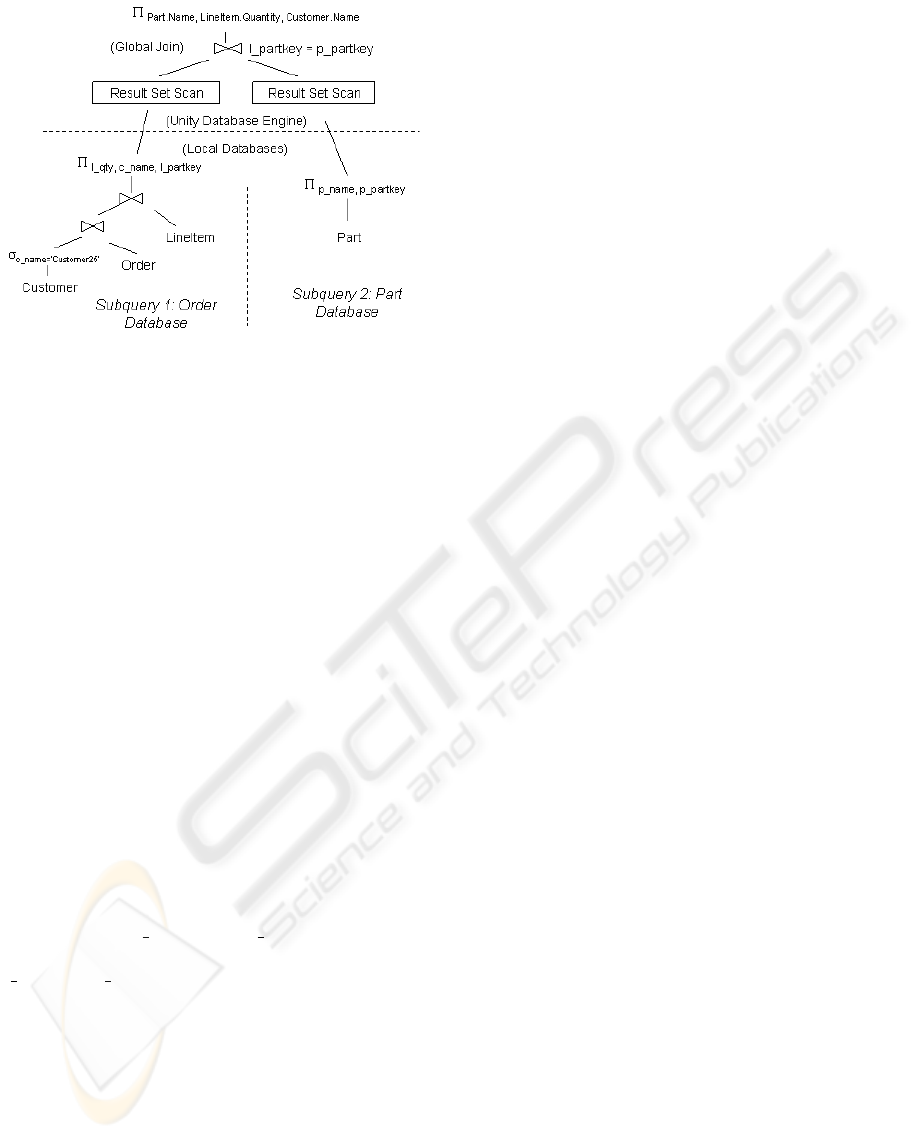
Figure 6: Operator Execution Tree
relating global keys. A global key is a key that iden-
tifies an object beyond the scope of the database. For
instance, a book ISBN is a key that can be used to
match book records across databases. In the annota-
tion of Figure 3, global keys are identified by spec-
ifying the scope where they are valid. The primary
key for the Part relation has the scope of the organi-
zation that owns the database. A global join is found
between two databases if the key fields match and the
scope of the global keys is compatible. Since both of
the databases contain the Part.Id key with a shared do-
main and a valid scope, Part.Id is the global key used
to join the subquery results. If no global joins exist,
the user could explicitly specify global join conditions
or a cross-product is performed. The plan of execu-
tion for the global query is represented in the operator
tree shown in Figure 6.
The driver implements the execution tree by exe-
cuting the two subqueries through JDBC drivers to
the data sources to retrieve both ResultSets. The Re-
sultSets are combined based on the Part.Id global
join. Notice that l
partkey and p partkey are included
in the subqueries in order to execute the global join
p partkey = l partkey. A global ResultSet is then con-
structed, which is accessed by regular JDBC methods,
as shown in lines 12-15 of the example program.
The embedded database engine uses the Result-
SetScan operator to scan in a JDBC ResultSet for
each subquery one row at a time. The subqueries
are threaded and executed in parallel. The optimizer
pushes as much work as possible to the individual
database sources, so that only the necessary global
joins and filtering/sorting is performed at the client.
Joins in the embedded database engine are performed
using either sort-merge join or a variant of adaptive
hash join. The database engine will use secondary
storage to handle large joins that do not fit in mem-
ory efficiently. The global join of the sample query
is processed by the database engine using a variant of
adaptive hash join (Zeller and Gray, 1990).
3.3 Supporting Evolution
The driver supports two types of evolution: addi-
tion/deletion of data sources and schema evolution
within a data source. Evolution is supported because
all mappings are calculated dynamically: mappings
from global concept names to fields in local sources,
joins between tables in each local database, and global
joins connecting databases. Annotating schemas be-
fore they are integrated reduces naming conflicts and
allows the renaming of schema constructs. Since joins
are calculated within a data source at query-time,
structural evolutions such as promoting a 1:N rela-
tionship to a M:N relationship are handled. Finally,
the conceptual query language on the global schema
only references attributes, so if the global schema
evolves, the query system will update the mappings
without affecting existing queries.
3.4 Detecting Inconsistent Data
The architecture is designed to detect inconsistent
data across data sources. It is common that names,
addresses, and other text fields may have distinct val-
ues in several databases. For every data item pro-
duced in the global result, the provenance of the data
item can be maintained. This allows a global user to
determine the data source for each data element and
the properties of that data source. It also allows the
system to detect when two data sources have differ-
ent values for the same field and present those differ-
ences to the global user. The user can then choose
which data value to accept. Support for inconsistent
data is unique to our architecture as other data integra-
tion systems assume their is no inconsistency between
sources. Due to the cost of tracking data provenance,
the user has the option of disabling this feature.
4 EXPERIMENTAL EVALUATION
The speed of global view construction and support
for data source evolution is tested in the first exper-
iment. In this experiment multiple TPC-H schemas
are integrated. The results in Figure 7 show the times
to integrate schemas (create the global schema), con-
nect to all databases, parse the conceptual query, and
generate the subqueries. The process for integrat-
ing schemas into a global schema is a linear time
process based on the number of schemas integrated.
The test is representative as integrated schemas will
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER
331

likely have data elements that share a large portion of
the same domain.
Integrate Parse Total
Schemas Schemas Connect Subqueries Time
2 0.219 0.203 0.110 0.532
3 0.235 0.234 0.125 0.594
10 0.485 0.437 0.406 1.328
100 1.375 1.719 5.063 8.157
Figure 7: Integration of TPC-H Schemas in Seconds
The time to parse the global query into subqueries
has a greater complexity and processing time due to
global inference. However, the time to parse and in-
fer 100 SQL subqueries is completed in five seconds.
The test results show that the Unity driver is capa-
ble of handling rapid evolution of the global schema,
either within a single data source or by the addition
or removal of data sources, as schema rebuilding is
extremely fast. One hundred medium sized schemas
may be integrated in less than 1.5 seconds and con-
nected in three seconds. Note that the global view is
created only once, whereas the parsing of the concep-
tual query and subquery generation is done for each
global query.
In order to evaluate the query execution times for
the Unity driver duplicate copies of the partitioned
TPC-H benchmark databases with a 1 GB database
size were installed on two identical computers run-
ning Microsoft SQL Server. A third identical com-
puter executed the Java test programs, where each
time was averaged over five query executions. The
query execution times shown in Figures 8 and 9 are
described below:
• TPC-H - Conceptual query executed through Unity
driver against a single source TPC-H database.
• JDBC TPC-H - SQL query equivalent to concep-
tual query executed directly through SQL Server
JDBC driver on a single source TPC-H database.
• Partitioned Separate Computers - Conceptual
query executed on TPC-H data set partitioned into
the Part and Order databases shown in Figure 2.
• Partitioned on One Computer - Conceptual
query executed on TPC-H data set virtually parti-
tioned into the Part and Order databases shown in
Figure 2 on a single computer.
Two similar queries with contrasting result set sizes
are used to evaluate the time required for Unity
to process a conceptual query including execution
time. The large (Figure 8) conceptual query SE-
LECT p
name, l quantity, c name with equivalent
SQL query
4
returns 6,001,215 tuples (equivalent to
4
SELECT p
name, l quantity, c name FROM part,
Figure 8: Large Part-LineItem-Customer Query
Figure 9: Small Part-LineItem-Customer Query
Lineitem table size). The smaller (Figure 9) query
shown in the example program of Figure 5 generates
the same results limited to Customer
25 for a result
size of only 76 tuples
5
. The overhead for Unity to
convert the conceptual query (TPC-H) into the equiv-
alent SQL query listed (JDBC TPC-H) requires less
than 0.025 seconds (25 ms) for either query. This
demonstrates the nearly negligible time to pass a con-
ceptual query through the Unity driver on a single
source.
lineitem, customer, orders WHERE p partkey=l partkey
and o
orderkey=l orderkey and c custkey= c custkey
5
SELECT p
name, l quantity, c name FROM part,
lineitem, customer, orders WHERE p
partkey=l partkey
and o
orderkey=l orderkey and c custkey= c custkey and
c
name = ’Customer#000000025’
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
332

The Figure 8 query execution times for the parti-
tioned databases executed faster than the same query
executed on a single source TPC-H database. The dif-
ference is due to the fact that the embedded database
in Unity executes one of the joins on the client ma-
chine, as opposed to the server performing all three
joins. The query executing all three joins on the server
involves the join of the large Lineitem relation requir-
ing full use of the CPU on the server. For the parti-
tioned databases Unity is able to start the global join
once the smaller ResultsSet from the Part relation is
received. This allows for the embedded database in
Unity to work in parallel with the server yielding an
improved execution time for this particular query.
The results in Figure 9 show a longer execution
time for integration versus full execution on the single
source TPC-H database. The increased time is due to
the time to transport to the client the entire Part rela-
tion (1.3 seconds) from the Part database in order to
complete the global join. The single source query im-
ports only the 76 tuples in the final result. Also, the re-
sults for the integration of the partitioned data located
on one computer takes slightly longer than data parti-
tioned on different computers, as the same resources
are shared on a single computer.
5 CONCLUSION
The Unity JDBC driver provides an automatic and
scalable approach to integrate and then query multiple
data sources. The JDBC interface provides standard
methods to access the data. The ability to quickly re-
compute the global view allows for dynamic integra-
tion of a large number of databases. The lightweight
database engine embedded in the driver integrates the
data from multiple databases transparently. The addi-
tion of the conceptual query language allows queries
to be specified on the global view without the require-
ment of understanding the structure of each under-
lying schema. Experimental results show that this
approach causes minimal overhead in the querying
process. In addition, the driver efficiently executes
the queries by identifying the subqueries to execute
on the servers and using the client to complete the
integration. This unique approach allows integration
to be more automated, scaleable, and rapidly deploy-
able.
Future work will investigate a more powerful
global query optimizer. By obtaining information
about the data sources including selectivity and re-
lation size, the global join strategy could be opti-
mized. In addition, strategies to effectively implement
GROUP BY queries will be examined.
REFERENCES
Collet, C., Huhns, M., and Shen, W.-M. (1991). Resource
Integration Using a Large Knowledge Base in Carnot.
IEEE Computer, 24(12):55–62.
Covitz, P., Hartel, F., Schaefer, C., Coronado, S., Fragoso,
G., Sahni, H., Gustafson, S., and Buetow, K. (2003).
caCORE: A common infrastructure for cancer infor-
matics. Bioinformatics, 19(18):2404–2412.
Decker, S., Erdmann, M., and Studer, R. (1998). ONTO-
BROKER: Ontology based access to distributed and
semi-structured information. In Database Semantics
- Semantic Issues in Multimedia Systems, volume 138
of IFIP Conference Proceedings. Kluwer.
Dragut, E. and Lawrence, R. (2004). Composing map-
pings between schemas using a reference ontology. In
ODBASE.
Goh, C., Bresson, S., Madnich, S., and Siegel, M. (1999).
Context Interchange: New Features and Formalisms
for the Intelligent Integration of Information. ACM
Transactions on Information Systems, 17(3):270–293.
Goldman, R., Shivakumar, N., Venkatasubramanian, S., and
Garcia-Molina, H. (1998). Proximity Search in Data-
bases. In VLDB, pages 26–37.
Haas, L., Lin, E., and Roth, M. (2002). Database Integration
through Database Federation. IBM Systems Journal,
41(4):578–596.
Halevy, A. (2001). Answering queries using views: A sur-
vey. VLDB Journal, 10(4):270–294.
Kirk, T., Levy, A., Sagiv, Y., and Srivastava, D. (1995). The
Information Manifold. In AAAI Spring Symposium on
Information Gathering.
Lenzerini, M. (2002). Data Integration: A Theoretical Per-
spective. In PODS, pages 233–246.
Li, C., Yerneni, R., Vassalos, V., Garcia-Molina, H.,
Papakonstantinou, Y., Ullman, J., and Valiveti, M.
(1998). Capability Based Mediation in TSIMMIS. In
ACM SIGMOD, pages 564–566.
Rahm, E. and Bernstein, P. (2001). A survey of ap-
proaches to automatic schema matching. VLDB Jour-
nal, 10(4):334–350.
Sheth, A. and Larson, J. (1990). Federated Database Sys-
tems for Managing Distributed, Heterogenous and
Autonomous Databases. ACM Computing Surveys,
22(3):183–236.
Ullman, J. (1997). Information Integration Using Logical
Views. In ICDT’97, volume 1186 of LNCS, pages 19–
40.
Wald, J. and Sorenson, P. (1984). Resolving the Query
Inference Problem Using Steiner Trees. TODS,
9(3):348–368.
Zeller, H. and Gray, J. (1990). An adaptive hash join al-
gorithm for multiuser environments. In VLDB 1990,
pages 186–197.
DYNAMIC DATABASE INTEGRATION IN A JDBC DRIVER
333
