
USING CORRESPONDENCE ASSERTIONS TO SPECIFY THE
SEMANTICS OF VIEWS IN AN OBJECT-RELATIONAL DATA
WAREHOUSE
Val
´
eria Magalh
˜
aes Pequeno, Joaquim Nunes Apar
´
ıcio
Depto. de Inform
´
atica, Centro de Intelig
ˆ
encia Artificial, Faculdade de Ci
ˆ
encias e Tecnologia, Universidade Nova de Lisboa
Quinta da Torre 2829 516, Caparica, Portugal
Keywords:
integrated information, object view, object-relational model, data warehouse.
Abstract:
An information integration system provides a uniform query interface for collecting of distributed and hetero-
geneous, possibly autonomous, information sources, giving users the illusion that they interrogate a centralized
and homogeneous information system. One approach that has been used for integrating data from multiple
databases consists in creating integrated views, which allows for queries to be made against them.
Here, we propose the use of C
orrespondence Assertions (CAs) to formally specify the relationship between
the integrated view schema and the source database schemas. In this way, CAs are used to assert that the
semantic of some schema’s components are related to the semantic of some components of another schema.
Our formalism has the advantages of proving a better understanding of the semantic of integrated view, and of
helping to automate some aspects of data integration.
1 INTRODUCTION
An Integration Information (II) system provides a uni-
form interface for querying collections of pre-existing
data sources that were created independently. In the
recent years, the number of applications requiring in-
tegrated access to several distributed, heterogeneous
information sources has immensely increased. A
wide range of techniques has been developed to ad-
dress the problem of information integration in data-
bases (Zhou et al., 1996; Goasdou
´
e et al., 2000).
Basically, there are two approaches to data integra-
tion: the virtual integrated views (Batini et al., 1986)
and the materialized integrated views (Zhou et al.,
1996). In the first one, data exits in the local sources
and the II system must reformulate the queries sub-
mitted to it, at run time, into queries against the
source schemas. The results from these queries on
the local sources are translated, filtered and merged
to form a global result and finally, the final answer
is returned to the user. Whereas, in the materiali-
zed approach, information from each source database
is extracted in advance and then translated, filtered,
merged and stored in a centralized repository, called
D
ata Warehouse (DW). Thus, when the user’s query
arrives, it can be evaluated directly at the repository,
and no access to the source databases is required.
There are some problems in integrating informa-
tion from multiple information sources. One of diffi-
culties is that, normally, the data have heterogeneous
structure and content. In this case, it is usual that the
integration systems are based on the specification of
a single integrated schema describing a domain of in-
terest. Additionaly, there is a set of source “descrip-
tions” (mappings) expressing how the content of each
source available to the system is related to the domain
of interest.
In our work, we used a formal object-relational
data model (Pequeno and Apar
´
ıcio, 2003) for mod-
eling the integrated view schema and source database
schemas of a data warehousing environment. We pro-
pose the use of the C
orrespondence Assertions (CAs)
to formally specify the relationship between the view
schema and the source database schemas. CAs are
a special kind of integrity constraints that are used
to assert the correspondence among schema compo-
nents. In our research, we use the view CAs to se-
mantically elucidate how the view objects are synthe-
sized from the source class objects. Our formalism is
advantageous in proving a better understanding of the
semantics of integrated view, and in helping to auto-
mate some aspects of data integration. In this paper
we focus on how the CAs can be used for helping to
generate the integrated view definition.
219
Magalhães Pequeno V. and Nunes Aparício J. (2005).
USING CORRESPONDENCE ASSERTIONS TO SPECIFY THE SEMANTICS OF VIEWS IN AN OBJECT-RELATIONAL DATA WAREHOUSE.
In Proceedings of the Seventh International Conference on Enterprise Information Systems, pages 219-225
DOI: 10.5220/0002507602190225
Copyright
c
SciTePress
Correspondence assertions to point out the seman-
tics of views already were developed for other works
(L
´
oscio, 1998; Vidal and Pequeno, 2000; Vidal et al.,
2001; da Costa, 2002). We extend the work of (Vidal
and Pequeno, 2000) to contemplate relational struc-
tures and aggregation functions. In (da Costa, 2002)
the CAs are used to assert the correspondence among
the view schema and the local sources schemas,
where these local sources schemas can be relational
or object-relational ones (like in our work). However,
to best of our knowledge, our paper is the first one to
specify CAs in O
bject-Relational(OR)data warehous-
ing environment, and to consider CAs between prop-
erties with aggregations functions.
The remainder of this paper is organized as fol-
lows. The next Section presents our formal model
1
.
Section 3 presents the formalism we use to assert the
relationship between the integrated view schema and
the source database schemas. Section 4 shows as CA
can be used to define the integrated view. Section 5
is devoted to present some previous approaches and
contrast them with ours. Finally, Section 6 concludes,
pointing out future work.
2 TERMINOLOGY
In this section, we present the basic concepts of the
object model used to represent the integrated view
schema and the source database schemas. This model
was based in O
bject-Oriented Data Model (OODM)
standard ODMG3 (Cattell et al., 2000), but we tried
to preserve the main characteristics of Relational Data
M
odel (RDM) proposed by Codd in (Codd, 1970).
In accordance with the object model described in
ODMG3, we distinguish objects from literals as fol-
lows: objects represent real world entities and have
a unique identifier (OID), while literals are special
types of objects that have no identifier.
An object is an instance of a type. Thus, types serve
as templates for their instances. In our model we de-
fine some types, namelly: base (integer, float, string
and boolean), reference, tuple and collections (set, list
and array). The tuple type is an important type be-
cause it can represent the relation schema in RDMs.
The component of the type tuple consists of pro-
perties, which can be classified into attributes and
relationships. The domain of an attribute is a lit-
eral or a collection of literals. On the other hand,
the domain of a relationship is an object or a collec-
tion of objects. Properties also can be classified into
singlevalued and multivalued. A property is denoted
singlevalued when each instance of its type can be
1
Only basic concepts are showed. For more details the
reader can refer to (Pequeno and Apar
´
ıcio, 2003).
related to at most one object (or literal) of the prop-
erty domain. A property is denoted multivalued when
each instance of its type can be associated to many
instances of the property domain. We consider the
properties whose types are base, reference or tuple
as singlevalued properties and the properties whose
types are collections (set, list or array) as multivalued
properties.
We distinguish types from classes. A class is a
set of objects that is associated with a type. We
distinguish two kinds of classes: the object classes,
whose instances of the type are objects; and the lit-
eral classes, whose instances of the type are literals.
It is common to present classes in diagrams
2
. In
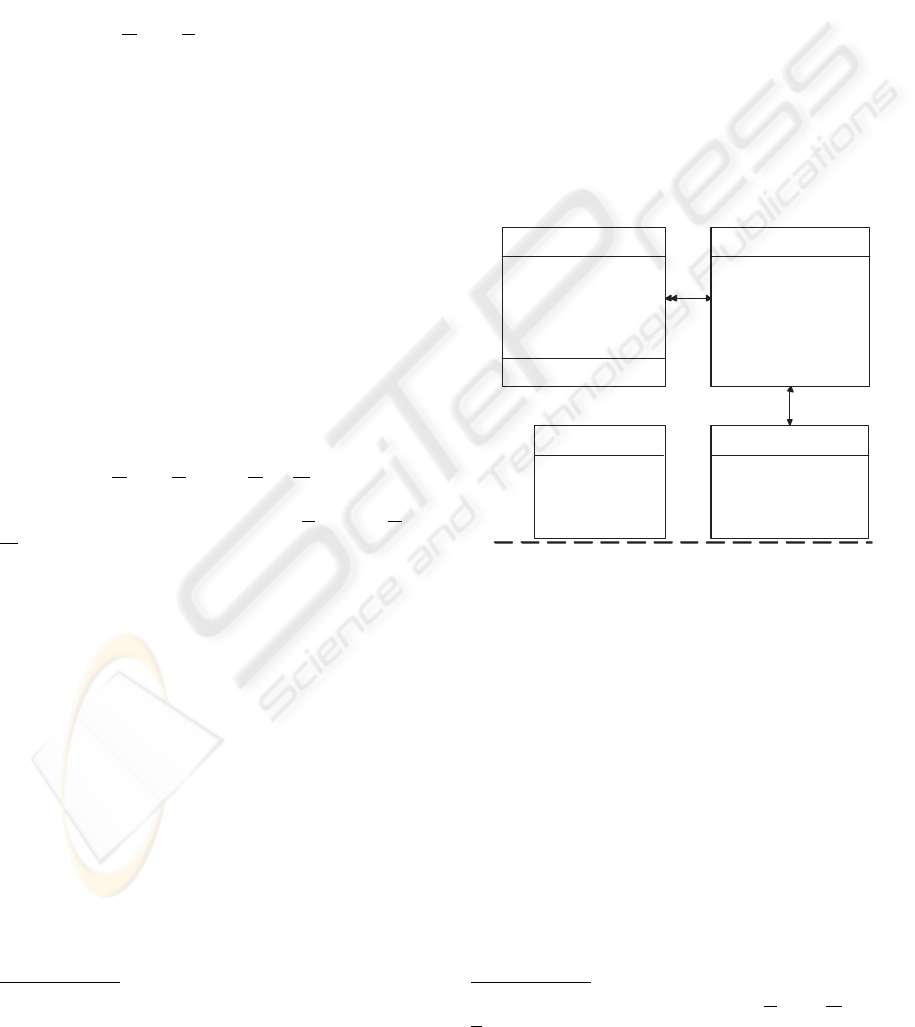
Figure 1, the classes EMPLOYEE, DIVISION, MANA-
GER and GOOD are represent as rectangles. The at-
tributes with their types are inside the rectangles. Sin-
gle arrows represent single valued relationships and
double arrows represent multi valued relationships.
DIVISION
divName
1
: string
shortForm
1
: string (K)
div
1
emp
1
mger
1
div
1
DB
1
EMPLOYEE
employeeName
1
:string
telephone
1
: {string}
identity
1
: integer (K)
salary
1
:float
addSalary
1
GOOD
number
1
: integer (k)
goodName
1
: string
sentPrice
1
: float
MANAGER
managerName
1
: string
identity
1
: integer (k)
Figure 1: An object-relational schema.
An OR schema is a set of class definitions that serve
as templates to generate the application domain ob-
jects. It is important to note that an OR schema can
be only a relational schema or an OR schema.
All classes in an OR schema have a distinct name, a
structured type, a finite set of signatures (the methods)
and an extension. The latter consists of a set of objects
that are members of a class at a given moment. An
instance of an OR schema S populates object classes
with OIDs, assigns values to the OIDs, assigns values
to literal class names, and assigns semantics to the
methods signatures.
Objects can be related through paths connecting
two or more properties. From Figure 1, one can ob-
serve that an employee is related to his/her division
manager through a path div
1
• mger
1
. We distinguish
2
The graphic notation is based on U
nified Modeling
L
anguage(UML) and ODMG3.
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
220
two kinds of paths: a reference path and a value path,
defined as:
Let C be a finite set of class names, P be a set of
properties names, T be a set of all types, props(C)
refers the set of properties defined for a class C and
dom(τ ) be the mapping that attaches to every type a
corresponding value set (domain).
Definition 1 (Reference path of a class) Let C
1
, C
2
,
..., C
n+1
in C, p
1
, ..., p
n
be properties in P and τ
1
,
..., τ
n
be types in T such that p
i
:τ
i
∈ props(C
i
), 1 ≤
i ≤ n. p
1
• p
2
• ... • p
n
is a reference path of C
1
iff
dom(τ
i
)= C
i+1
, 1 ≤ i ≤ n.
This means that instances of C
1
are related with the
instances of C
n+1
through the reference path p
1
• p
2
• ... • p
n
.
Definition 2 (Value path of a class) Let C
1
, C
2
, ...,
C
n+1
in C, p
1
, ..., p
n
be properties in P and τ
1
, ..., τ
n
be types in T such that p
i
:τ
i
∈ props(C
i
), 1 ≤ i ≤ n.
p
1
• p
2
• ... • p
n
is a value path of C
1
iff dom(τ
i
)=
C
i+1
, 1 ≤ i ≤ n − 1 and dom(τ
n
)= w, where w is
a constant or a collection of constants (integer, float,
string or boolean values).
This means that the instances of C
1
are related with
the value w (with domain of τ
n
) of some property
from C
n
through the value path p
1
• p
2
• ... • p
n
.
In Figure 1, div
1
• mger
1
is a reference path (for
class EMPLOYEE) and div
1
• mger
1
• managerNa-
me
1
is a value path (for class EMPLOYEE).
Now, we extend this model with the view classes
and view schema concepts, as follows. An view class
is defined as an object class derived from one or more
classes, called base classes (in a base schema). The
view class objects can be physically stored in a data-
base or not, and these objects can be the matching
of relational data or object-relational data from local
sources.
An integrated view schema, or simply view
schema, is formed by the set of view classes (from
one or more base schemas) and this view schema is
independent from its underlying schemas.
3 CORRESPONDENCE
ASSERTIONS
The C
orrespondence Assertions (CAs) of a view class
formally specify the relationships between the view
class and its base classes. In this way, CAs are used
to assert that the semantic of some schema compo-
nents are related to the semantic of some components
of another schema.
In our work, the relationship between the inte-
grated view schema and the source database schemas
can be specified by the following four kind of CAs:
E
xtension Correspondence Assertion (ECA), Object
C
orrespondence Assertion (OCA), Property Corres-
pondence A
ssertion (PrCA) and Path Corresponden-
ce A
ssertion (PaCA), described below. A formal de-
finition of these CAs can be found in (Pequeno and
Apar
´
ıcio, 2004).
3.1 Extension CAs
The ECAs are used to specify the relationship that
exists between the extension view class and exten-
sions base classes. Thus, the ECAS are used to define
which objects of the base classes should have a cor-
responding semantically equivalent object in the view
class. Two objects o
1
and o
2
are semantically equiva-
lent (o
1
≡ o
2
) if o
1
and o
2
represent the same object
in the real world.
We define the root classes of a view class V as all
the classes that are related to V through some ECA.
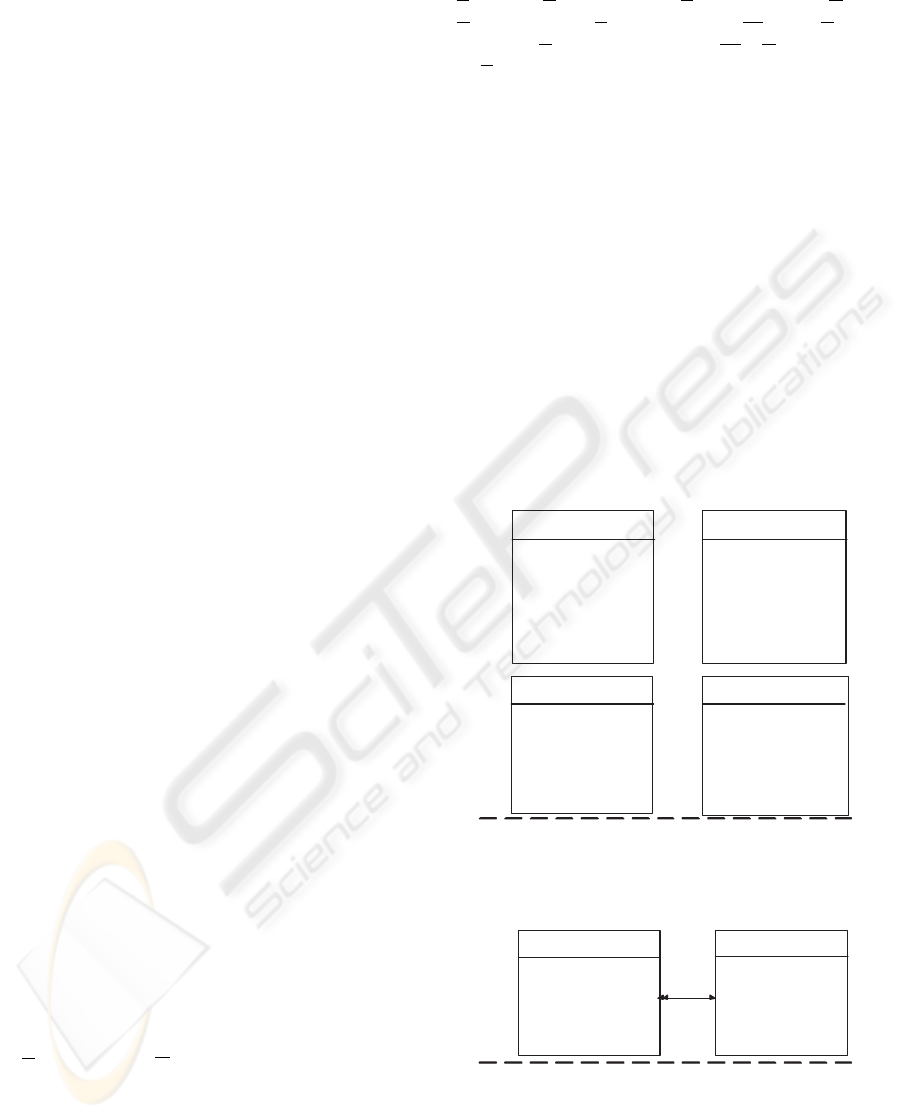
Consider, for example, the view class STUDENT
v
(see
Figure 2), which contain informations about all stu-
dents in a university, including his/her salary if the
student also works.
V
1
STUDENT
v
name
v
:string
telephone
v
: {string}
birthday
v
: string
salary
v
: float
ST&EMP
v
name
v
:string
birthday
v
: string
salary
v
: float
manager
v
: string
identity
v
:integer
number
v
:string
(k)
identity
v
:integer
number
v
:string
(k)
ST_COURSE
v
course
v
: integer
(k)
nameCourse
v
:{string}
students
v
: integer
ST_GOOD
v
quantity
v
:integer
sumPrice
v
: float
minPrice
v
: float
maxPrice
v
: float
avgPrice
v
:float
Figure 2: The integrated view schema V
1
.
STUDENT
name
2
:string
telephone
2
: {string}
birthday
2
: string
COURSE
std
2
cre
2
DB
2
cod
2
: integer
name
2
: string
identity
2
: integer
number
2
:string
(k)
Figure 3: The source database schema DB
2
.
The STUDENT
v
root classes are STUDENT in DB
2
(see Figure 3) and EMPLOYEE in DB
1
(see Figu-
re 1), which are related to STUDENT
v
through the
following ECAs: ψ
1
: STUDENT
v
≡ STUDENT and
USING CORRESPONDENCE ASSERTIONS TO SPECIFY THE SEMANTICS OF VIEWS IN AN
OBJECT-RELATIONAL DATA WAREHOUSE
221

ψ
2
: STUDENT
v
⊘ EMPLOYEE. ψ
1
specifies that STU-
DENT
v
and STUDENT are equivalent, i.e., for each
STUDENT object there is one semantically equivalent
object in STUDENT
v
, and vice-versa. ψ
2
specifies that
the classes STUDENT
v
and EMPLOYEE can have ob-
jects in common.
In accordance with the kind of ECA relating a view
class with its root classes, we distinguish six different
kinds of view classes: equivalence, selection, union,
difference, intersection and generalization.
3.2 Object CAs
The OCAs specify the matching function that exists
between the objects of a class with the object of ano-
ther class. These assertions define the conditions in
which an object of a class is semantically equivalent
to an object of another class.
In the case of ECAs, given two classes C
1
and C
2
to any state D there is a mapping function that defines
an one to one correspondence between the objects of
C
1
and C
2
. We can have others mapping functions,
maybe one that makes the relationship among seve-
ral objects of a class with one object of another class.
This is the case, for example, of the view class with
aggregation functions.
Object matching (Doan et al., 2003) is an impor-
tant aspect of data integration and it can be expen-
sive to compute. Most systems assumes that a uni-
versal key is available for performing object match-
ing. In this work, we do not address this problem and,
as proposed in (Zhou et al., 1996), we assume that
match criteria is defined by a high-level mechanism.
In case of view classes without aggregations it defines
1:1 correspondences between the objects in families
of corresponding classes.
3.3 Property CAs and Path CAs
The PrCAs and the PaCAs specify how the pro-
perties values of the view class objects are de-
rived from properties values of their root classes
objects. For instance, the property salary
v
of the
view class ST&EMP
v
(see Figure 2) is defined by
the PrCA: ST&EMP
v
.salary
v
≡ EMPLOYEE.salary
1
,
which specifies that given an instance s of ST&EMP
v
,
if there is an instance e in EMPLOYEE such s
≡ e, then s.salary
v
= e.salary
1
. The proper-
ty manager
v
of the class ST&EMP
v
is defined by
the PaCA ST&EMP
v
.manager
v
≡ EMPLOYEE.div
1
•
mger
1
• managerName
1
, which specify that given
an instance s of ST&EMP
v
, if there is an instance
e in EMPLOYEE such s ≡ e, then s.manager
v
=
e.div
1
.mger
1
.managerName
1
. Note that a view
class property can be associated with more than one
PrCA and/or PaCA. For instance, the property name
v
of the view class ST&EMP
v
has the following PrCAs:
ST& EMP
v
.name
v
≡ EMPLOYEE.employeeName
1
and ST&EMP
v
.name
v
≡ STUDENT.name
2
. This
means that the values of name
v
can be derived from
employeeName
1
and name
2
.
In a data warehousing environment, it is common
to have materialized views involving aggregation, be-
cause clients of DWs often want to summarize data
in order to analyze trends (Gray et al., 1995; V. Hari-
narayan, 1996). Thus, we define some PrCAs whose
properties values are gotten by aggregation functions.
These PrCAs are different from other CAs, for the
reason that there is no one to one correspondence
between the view schemas and the source database
schemas. Instead of this, there is a mapping of one
view class object to many root class objects.
At this point, we must extend the definition of a
root class to include the classes with aggregation.
Thus, we define the root classes of a view class V
as the set of all classes that are related to V through
some ECA or some PrCA with aggregation function.
In our work, the aggregation functions mentioned
are ones supported by the most of the queries lan-
guages, like SQL-3 (Fortier, 1999). The statistic ag-
gregation functions, as standard deviation and vari-
ance, are not considered in our work, although they
are supported in some OR databases (for instance, the
reader can refer to the work of (Chamberlin, 1996)).
We can distinguish six kinds of PrCAs with
aggregation: sum (summation), count, min (min-
imum), max (maximum), avg (average) and
group-by. In Figure 2, we can observe the view
classes: I) ST
GOOD
v
, which is a set of a sole
object and which is related to root class GOOD
through the PrCAs with aggregation, such that
Ψ
6
:ST
GOOD
v
.quantity
v
∼
=
count(GOOD) and
Ψ
7
:ST
GOOD
v
.sumPrice
v
∼
=
sum(GOOD.sentPrice
1
);
and II) ST
COURSE
v
, which is a set of objects and is
related to root class COURSE through the PrCA with
aggregation of group-by presented in Figure 4.
Ψ
8
:ST COURSE
v
(course
v
, nameCourse
v
,
students
v
)
∼
=
COURSE(M[name
2
]A[cod
2
]F[(count,std
2
)] ∧
course
v
→ COURSE.cod
2
∧
nameCourse
v
→ COURSE.name
2
∧
students
v
→ count(COURSE.std
2
)
Figure 4: A property CA with aggregation of group-by bet-
ween ST
COURSE
v
and COURSE.
In a PrCA with aggregation of group-by there are
notations that need some explanation. Thus, we
can specify this type of PrCA as following: V(p
1
,
...,p
n
, p’
1
, ..., p’
m
, p”
1
, ..., p”
k
)
∼
=
C(M[p
1
, p
2
,...,
p
n
]A[p’
1
, p’
2
, ..., p’
m
] F[(f
1
, p”
1
), (f
2
, p”
2
), ...,
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
222

(f
k
, p”
k
)]) ∧ V.p
1
→ C.p
1
∧ ... ∧ V.p
n
→ C.p
n
∧ V.p’
1
→ C.p’
1
∧ ... ∧ V.p’
m
→ C.p’
m
∧ V.p”
1
→ f
1
(C.p”
1
) ∧ ... V.p”
k
→ f
k
(C.p”
k
), where:
1. M[p
1
, p
2
,..., p
n
], with p
i
:τ
i
∈ props(C), 1 ≤ i ≤
n, is a list of properties of the root class defined in
C. Pay attention to M can be an empty list.
2. A[p’
1
, p’
2
, ..., p’
m
], with p’
i
:τ
′
i
∈ props(C), 1 ≤
i ≤ m, is a list of grouping properties of the root
class specified in C.
3. F[(f
1
, p”
1
), (f
2
, p”
2
), ..., (f
k
, p”
k
)], with p”
i
:τ ”
i
∈ props(C), 1 ≤ i ≤ k, is a list of (hfunctioni,
hpropertyi) pairs. In each pair, hfunctioni is one
of the allowed functions - such as sum, avg and
max - and hpropertyi is a property of the root class
defined by C. Observe that F can be an empty list.
4 USING CAs TO DEFINE
VIRTUAL VIEW CLASSES
In our approach, the integrated view schema of a DW
consists of three steps:
1. Integrated view modeling - Analyzes the require-
ments and specifies the integrated view schema
using a high-level data model. In this work,
we use our OR data model to represent the inte-
grated view schema (Pequeno and Apar
´
ıcio, 2003).
The graphic notation used is based on UML and
ODMG3.
2. View correspondence assertions generation -
Combines the integrated view schema with the lo-
cal schemas in order to identify the CAs that for-
mally assert the relationships between the inte-
grated view schema and the source schemas. To
achieve this, all schemas should be expressed in the
same data model (called “common” data model).
3. Integrated view definition - Generates the inte-
grated view definition based on the integrated view
schema and the view CAs. The integrated view de-
finition consists of a set of queries, when the view
classes are virtual, and a set of rules that maintain
the view classes to reflect updates occurred in root
classes, when the view classes are materialized.
To illustrate our approach, consider the integrated
view schema V
1
in Figure 2, which integrates infor-
mation from employees in DB
1
(see Figure 1) and
students in DB
2
(see Figure 3).
The next step in the process of building the inte-
grated view V
1
is generating the view correspondence
assertions. This process consists of following steps:
1. Identify the Extension CAs.
2. For each ECA ψ identified in step 1, where ψ re-
lates the view class V
1
, whose objects are of the
type τ
v1
, to root class C
1
, whose objects are of the
type τ
c1
, do:
(a) Identify the Object CAs from view class objects
V
1
to objects in C
1
.
(b) Compare the types τ
c1
and τ
v1
. In this step the
types τ
c1
and τ
v1
are compared and the Proper-
ties CAs and Path CAs are identified.
3. Identify the Properties CAs with aggregation.
4. For each Property CA with aggregation ψ identified
in step 3, where ψ relates the view class V
2
to root
class C
2
, do:
(a) Identify the matching function between view
class objects V
2
to objects in C
2
.
Some examples of PrCAs are shown in Figure 5.
Ψ
9
:STUDENT
v
.number
v
≡STUDENT.number
2
Ψ
10
:STUDENT
v
.identity
v
≡STUDENT.identity
2
Ψ
11
:STUDENT
v
.name
v
≡STUDENT.name
2
Figure 5: Some view PrCAs among STUDENT
v
and STU-
DENT
The final step in the process of building an inte-
grated view is the generation of the integrated view
definition. In our approach, the integrated view is
defined based on the integrated view schema and the
view correspondence assertions.
As we already mentioned, a view class V can be
implemented as a virtual class as well as a materi-
alized one. If V is virtual, then the definition of this
class is determined from its root classes using its CAs.
Otherwise, it is materialized and an extension to this
class is explicitly created and rules to maintain V (to
reflect updates occurred in its root classes) are gene-
rated. In this paper, we only present definitions to the
queries to virtual view classes. Mechanisms to main-
tain materialized view classes are going to be investi-
gated in the next stage of our research.
During the search for a query representation, seve-
ral queries languages (SQL-3(Fortier, 1999), ODMG
OQL(Cattell et al., 2000) and O
2
View(dos Santos,
1994)) were considered, but none query representa-
tion has the expressivity necessary to define our view
classes. Thus, we decide to use a combination of the
SQL-3 and ODMG OQL query languages for the de-
finition of our virtual view classes. SQL-3 is an OR
database language, which is a model flexible enough
to represent and store any data type supported by re-
lational and OO models, as well as some in between.
ODMG OQL is an OO database language and it is
very close to SQL-2. Despite of these choices our
approach can be used to denote virtual view classes
definitions in any other languages.
USING CORRESPONDENCE ASSERTIONS TO SPECIFY THE SEMANTICS OF VIEWS IN AN
OBJECT-RELATIONAL DATA WAREHOUSE
223

create row type TSTUDENT
v
(
number
v
int,
name
v
char(30),
identify
v
char(11),
telephone
v
set(char(9)),
birthday
v
char(8),
salary
v
float,
);
Figure 6: STUDENT
v
type of view class definition.
create view STUDENT
v
of TSTUDENT
v
as select S.number
2
, S.name
2
, S.identity
2
,
S.telephone
2
, S.birthday
2
, E.salary
1
from STUDENT S in DB
2
left outer join
EMPLOYEE E in DB
1
on S.identity
2
= E.identity
1
Figure 7: STUDENT
v
view class definition.
Figure 7 presents the definition for the view class
STUDENT
v
. It extracts information about employees
and students from the local sources DB
1
and DB
2
,
respectively. Keep attention to the fact that the view
class STUDENT
v
is of the type TSTUDENT
v
(see Figu-
re 6). As we can observe, the clause “from” of the def-
inition for STUDENT
v
correctly implements an equiv-
alence view as specified by the ECA ψ
1
, which has
some objects in common with another class (as speci-
fied by the ECA ψ
2
. In this case, the equivalence view
represents a left outer join view. The clause “select”
of this definition is denoted based on PrCAs such that:
ψ
9
, ψ
10
and ψ
11
(see Figure 5). The clause “on” of
this definition is denoted based on an object CA be-
tween STUDENT and EMPLOYEE.
5 RELATED WORK
There is large extension of related literature on in-
formation integration in databases, such that: Her-
mes(Subrahmanian et al., 1995) and Garlic(Carey
et al., 1995). The focus of all these systems are on
building a data integration architecture based on me-
diators(Wiederhold, 1992). The mediator concept is
slightly different from the DW. Mediators, normally,
are built to provide an integrated and transparent ac-
cess to heterogeneous and possibly distributed data
sources, and primarily are used in operational data en-
vironment. DWs provide an integrated access to data
derived from operational data and primarily are used
to support the decision-marking activities.
The majority of the works found in the litera-
ture focus on relational DWs((Iqbal et al., 2003)).
To the best of our knowledge, there is only one
work closely related to ours: the O
bject-Relational
Da
ta Warehousing System (ORDAWA)(Czejdo et al.,
2001). Their approach, with regard to the problem
of integrating of heterogeneous data in a DW con-
sists on: 1) definition of an OO view schema; 2) de-
velopment of data structures called: C
lass Mapping
S
tructure(CMS), Object Mapping Structure(OMS),
and Log. CMS is used to store derivation links bet-
ween the view classes and their root classes. OMS is
used to identify the object matching between the view
classes and their root classes. Log is used to record
modifications made to root classes objects.
The aim of the data structure OMS in ORDAWA
is the same of Object CAs: to indicate when two ob-
jects are the same in the real world. Already the role
of CMS in ORDAWA is like our ECAs, PrCAs and
PaCAs, but our CAs are better in following aspects:
• They give us a clear notions of the relationship bet-
ween the integrated view schema and the source
database schemas, i.e., the designer/user has a bet-
ter understanding of the semantics associated with
the integrated view;
• They can assist the process of generating the inte-
grated view definition;
• They give us a high-level and language-indepen-
dent specification of an integrated view.
Seemingly, both approaches mention the same
kinds of view classes, but an issue addressed in this
paper that has not been addressed in ORDAWA is
the support to view classes with aggregation function,
which is an important issue in DW environment.
6 CONCLUSIONS
In this paper, we propose the use of C
orrespondence
A
ssertions (CAs) to formally assert the relationship
between the integrated view schema and the source
database schemas. An advantage of using CAs is that
they allow for the specification of the integrated view
in a formal and language-independent way. More-
over, they provide designers/users a better under-
standing of the semantic associated with the inte-
grated view.
We have showed how the CAs can be used for
aiding the generation of the integrated view defini-
tion. This process was illustrated with some exam-
ples showing how to generate queries (when the
view classes are virtual) based on the integrated view
schema and view CAs.
ICEIS 2005 - DATABASES AND INFORMATION SYSTEMS INTEGRATION
224

As future work, we will investigate how the CAs
can be used to automate the maintenance of the inte-
grated view, when the view classes are materialized.
Another important direction for future work is the de-
velopment of an object-relational algebra to specify
view classes. Additionally, we intend to extend our
data model to contemplate view schema and view
class definitions.
REFERENCES
Batini, C. et al. (1986). A comparative analysis of method-
ologies for database schema integration. ACM Com-
puting Surveys, 18(4):323–364.
Carey, M. J. et al. (1995). Towards heterogeneous multi-
media information systems: The Garlic approach. In
International Workshop on Research Issues in Data
Engineering - Distributed Object Management, pages
124–131.
Cattell, R. et al. (2000). The object database standard
ODMG 3.0. Morgan Kaufmann Publishers.
Chamberlin, D. D. (1996). Using the new DB2 - IBM’s
object-relational database system. Morgan Kauf-
mann.
Codd, E. F. (1970). A relational model of data for large
shared data banks. In Communications of the ACM,
pages 377–387.
Czejdo, B. D. et al. (2001). Design of a data warehouse
over object-oriented and dynamically evolving data
sources. In 12th International Workshop on Database
and Expert Systems Applications, pages 128–132.
da Costa, J. P. (2002). Gerando tradutores para a atualizac¸
˜
ao
de banco de dados atrav
´
es de vis
˜
oes de objetos. Mas-
ter’s thesis, Federal University of Ceara, Brazil.
Doan, A. et al. (2003). Object matching for information in-
tegration: a profiler-based approach. In Proc. of Work-
shop on Information Integration on the Web.
dos Santos, C. (1994). Design and implementation of an
object-oriented view mechanism. Technical report,
Institut National de Recherche en Informatique et en
Automatique, France.
Fortier, P. (1999). SQL3 - Implementing the SQL foundation
standar. McGraw-Hill, EUA.
Goasdou
´
e, F. et al. (2000). The use of CARIN language
and algorithms for information integration: the PIC-
SEL system. International Journal of Cooperative In-
formation Systems, 9(4):383–401.
Gray, J. et al. (1995). Data cube: A relational aggregation
operator generalizing group-by, cross-tab, and subto-
tals. Technical Report msr-tr-95-22, Microsoft.
Iqbal, S. et al. (2003). Distributed heterogeneous relational
data warehouse in a grid environment. The Computing
Research Repository (CoRR) cs.DC/0306109.
L
´
oscio, B. F. (1998). Atualizac¸
˜
ao de m
´
ultiplas bases de
dados atrav
´
es de mediadores. Master’s thesis, Federal
University of Ceara, Brazil.
Pequeno, V. M. and Apar
´
ıcio, J. N. (2003). A formal model
for object-relational databases. In Proceedings of the
5th International Conference on Enterprise Informa-
tion Systems(ICEIS), volume 1, pages 327–333.
Pequeno, V. M. and Apar
´
ıcio, J. N. (2004). Using corre-
spondence assertion to specify the semantics of views
in an object-relational data warehouse. Technical re-
port, New University of Lisbon.
Subrahmanian, V. et al. (1995). HERMES: A heterogeneous
reasoning and mediator system. Technical report, Uni-
versity of Maryland.
V. Harinarayan, A. Rajaraman, J. U. (1996). Implement-
ing data cubes efficiently. In Proceedings of the ACM
SIGMOD Conference.
Vidal, V. et al. (2001). Using correspondence assertions for
specifying the semantics of XML-based mediators. In
Workshop on Information Integration on the Web, vol-
ume 3(11).
Vidal, V. and Pequeno, V. (2000). Self-maintanance of
match classes in integrated views. In Anais do XV
Simp
´
osio Brasileiro de Banco de Dados, Brasil.
Wiederhold, G. (1992). Mediators in the architecture of fu-
ture information systems. In IEEE Computer, volume
25(3), pages 38–49.
Zhou, G. et al. (1996). Generating data integration medi-
ators that use materialization. Journal of Intelligent
Information Systems, 6(2/3):199–221.
USING CORRESPONDENCE ASSERTIONS TO SPECIFY THE SEMANTICS OF VIEWS IN AN
OBJECT-RELATIONAL DATA WAREHOUSE
225
