
MODELING PREFERENCES ONLINE
Maria Cleci Martins
1
and Rosina Weber
2
1
College of Businees, Brazilian Lutheran University R. 15 de Novembro, 253 Novo Hamburgo, RS 93315 Brazil
2
College of Information Science & Technology, Drexel University 3141 Chestnut Street Philadelphia, PA 19104 USA
Keywords: E-Commerce, Discrete choices, Stated preferences, Personalization, Ontologies, User modeling
Abstract: The search for an online product that matches e-shoppers’ needs and preferences can be frustrating and
time-consuming. Browsing large lists arranged in tree-like structures demands focused attention from e-
shoppers. Keyword search often results in either too many useless items (low precision) or few or none
useful ones (low recall). This can cause potential buyers to seek another seller or choose to go in person to
a store. This paper introduces the S
POT (Stated Preference Ontology Targeted) methodology to model e-
shoppers’ decision-making processes and use them to refine a search and show products and services that
meet their preferences. SPOT combines probabilistic theory on discrete choices, the theory of stated
preferences, and knowledge modeling (i.e. ontologies). The probabilistic theory on discrete choices coupled
with e-shoppers’ stated preferences data allow us to unveil parameters e-shoppers would employ to reach a
decision of choice related to a given product or service. Those parameters are used to rebuild the decision
process and evaluate alternatives to select candidate products that are more likely to match e-shoppers’
choices. We use a synthetic example to demonstrate how our approach distinguishes from currently used
methods for e-commerce.
1 INTRODUCTION
The search for an online product that matches e-
shoppers’ needs and preferences can be frustrating
and time-consuming. Information about products
and suppliers is usually accessed from database
servers using either list browsing or keyword search.
However, the amount of information available in
those databases has substantially increased the
cognitive effort required for e-shoppers to make
their choices. Browsing large lists, arranged in tree-
like structures can be time consuming, while
keyword search often results in too many useless
items and too few actually useful (or none) being
returned. Thus, instead of facilitating the choice (and
the sale), the Internet makes the e-shopper’s choice
decision-making process more difficult. Such
difficulty is frustrating and is detrimental to online
sales.
Addressing customers’ needs is crucial for e-
commerce. E-commerce systems should be able to
facilitate the customers’ choice process by offering
alternatives that are more likely to satisfy their
preferences. This would generate less frustration and
potentially increase revenues, service level and
customer’s satisfaction.
Personalization is an approach that uses
characteristics of individual users to select
information to be searched and displayed to users
(Cotter & Smyth 2000). Recommender systems for
e-commerce (e.g., Ardissono & Godoy 2000;
Domingue et al. 2002, Burke 2000) address the
personalization issue by filtering the amount of non-
requested products to be showed to the e-shopper in
a given session. Recommender systems can be
collaborative, content-based, demographic, utility-
based, and knowledge-based (Burke 2002).
Recommender systems are useful when
customers do not know exactly what product or
service they need, or when the company wants to
introduce different products to the user. However,
when customers roughly know their needs and the
type of product or service to address those needs, the
problem is to find the best available online option
according to the user’s viewpoint. This problem is
typically addressed only by utility-based
recommender systems (Burke 2002). As a
comparison, in a physical store, the shopper would
be able to use other senses (e.g. vision, touch) to
recognize available products and compare them
255
Cleci Martins M. and Weber R. (2005).
MODELING PREFERENCES ONLINE.
In Proceedings of the First International Conference on Web Information Systems and Technologies, pages 255-262
DOI: 10.5220/0001230702550262
Copyright
c
SciTePress

before choosing one, or ask a sales person for
advice. On the Internet, however, they have to rely
on their decision-making skills and the available
information to choose the best option.
This paper proposes the use of the economic
theory on discrete choices (Ben-Akiva & Lerman
1985) to help e-shoppers find the best match for
their needs from what is available on the Internet. In
this sense, it can be categorized as an utility-based
recommender. Our approach is to elicit from e-
shoppers how they make choices, build a model of
their choice behaviour, and use it to refine the
search and show products and services that meet
their preferences.
Discrete choice modeling has been largely used
in the transportation field to forecast travel demand
from disaggregate data on individual choices (Ben-
Akiva & Lerman 1985; Fowkes & Shinghal 2002).
For example, it is used to forecast demand by
finding the likelihood that a travel mode is chosen
given certain characteristics such as travel time,
comfort, and headway. The rationale for using
discrete choice modeling is that it is a mature
methodology to uncover users’ decision-making
processes without asking them directly.
The mathematical model − Logit is very robust
and it is likely that the user’s decision-making model
found is the best possible (Ben-Akiva & Lerman
1985). Alternative methods (e.g. non-linear) are
computationally more complex, more demanding to
the user, and their result has been shown to be only
marginally better (De Carvalho, M. 1998).
Section 2 reviews methods used in this work:
discrete choice modeling, stated preference,
ontologies, and personalization. The S
POT
methodology is described in Section 3, followed by
a demonstration that uses statistics-based simulation
in Section 4; Section 5 is a discussion and Section 6
concludes.
2 METHODS
2.1 Discrete Choice Theory
The term choice refers to the cognitive process of a
consumer who, after evaluating the alternatives in a
choice set, decides to select one of them (Louviere
1988). Discrete choice modeling is a well-known
and mature methodology (Ben-Akiva & Lerman
1985) to investigate that process. The main feature
of discrete choice data is that the observed response
(i.e. the dependent variable) is discrete: the method
only determines whether or not customers choose
one alternative option.
Discrete choice models can use compensatory or
non-compensatory rules. Compensatory models
allow offsetting changes in one or more attributes to
compensate for a change in a particular attribute
(implying simultaneous consideration of all
attributes). For instance, a roomier seat can
compensate for a higher price in air travel. By
contrast, non-compensatory models do not permit
trade-offs between attributes; comparisons are made
on a sequential consideration of each attribute. The
last decision is often based on a compensatory
model to compare final options (if more than one).
This is the decision-making situation faced by e-
shoppers on the Internet.
Discrete choice modeling is based on the
economic utility theory for compensatory models
with the following four assumptions about the
consumer behaviour.
1. Products or services can be represented in vectors
of feature-value pairs (attributes), e.g. cost, brand.
2. Customers are optimizers and they compare
options based on the value of their attributes.
3. Customers make trade-offs between attributes of a
product/service to reach their decision, e.g. in
transport service, less comfort can be accepted if the
fare is reduced.
4. Customers are maximizers and they always
choose the best perceived option within a knowledge
domain.
2.2 Stated Preference
Stated Preference (SP) is a technique used to collect
data on individual’s discrete choices (Pearmain &
Kroes 1990). It can be understood as a simulation
game where individuals are asked to state their
preferences for a set of possible options (i.e. choice
set). A choice set is composed of at least two
alternatives e.g. a trip can be characterized by the
attributes cost and in-vehicle travel time. A choice
set would consider the transportation modes car and
train, each mode being represented by its respective
cost and travel time. The number of choice sets is
developed according to the number and levels of
attributes to be considered.
The design of a SP collection must consider
trade-offs between attributes of the product or
service. Respondents should be given choice sets
with possible options, but it is not necessary to know
exactly which options are available and the exact
values of the attributes; the attribute values should
be as close to reality as possible. An Internet
collection can be designed at runtime (e.g. using the
support of a knowledge base).
WEBIST 2005 - WEB INTERFACES AND APPLICATIONS
256
A desired property of a SP collection is
orthogonality (zero correlation between attribute
values and alternatives), so that separate effects on
choices can be estimated, as well as possible
interaction effects of their combinations. For the
sake of demonstration (Section 4) we are employing
a full factorial design that guarantees orthogonality
(Kocur et al. 1982). On a real situation, fractional
designs have to be employed to reduce the
respondents’ fatigue. Factorial design provides a
way to investigate the interaction effects between
attributes, such as price and travel time. To measure
all interaction effects one should use a full factorial
design, which is a problem that grows exponentially.
Fractional factorial designs are employed to reduce
dimension and the number of alternatives users have
to analyse. In that case, some minor interaction
effects are ignored in the experiment.
In our proposed approach, customers’ stated
preference data is used to calibrate a Logit model
(Ben-Akiva & Lerman 1985) that will unveil the
parameters (weights) that the e-shopper would use to
evaluate and choose one online option.
2.3 Logit Modeling
Logit modeling assumes that options are represented
by a function (U
i
) composed of unobserved variables
(β
j
), which are somehow associated with
characteristics (X
ij
) of the product (i) and a random
term (ε)(See Equation 1). The function U might be
continuous or not, depending on the type of the
attributes. If price is continuous and colour is
discontinuous, then a function with both these
variables would necessarily be discontinuous at
some point. The values of the coefficients are found
from data containing trade-offs between attributes
that are therefore incorporated into the modeling.
),(
εβ
ijji
XfU =
Equation (1)
The coefficients (β) on the observed characteristics
(X
ij
) in the utility function (U
i
) are estimated with an
optimization procedure such as Newton-Raphson
(Ben-Akiva & Lerman 1985). The exponential
behaviour (e) is employed to explain predicted
probabilities (P
i
) of a particular response (“buy” or
“not buy”) regarding an alternative “i” (See
Equation 2) belonging to the choice set with “J”
options. Thus, the likelihood that an alternative is
chosen is expressed as a function of its attributes and
the other options available in the choice set.
∑
=
j
U
Ui
i
j
e
e
P
Equation (2)
As maximizers, individuals place their preferences
in the alternative they recognize as having the
highest utility value (U
i
> U
j
). The analyst uses the
modeling approach to be able to find the likely
coefficients underneath the decision that has
determined the choice. Considering that some of the
variables influencing the choice might not have been
accounted for, a random term is added to the model.
In case of Logit, Luce (1959) has shown that the
random term is independent and identically
distributed according to the Weibull distributions.
This means that alternatives are uncorrelated and
also independent. We will use this characteristic of
the model as the base to create synthetic data and
demonstrate our approach (Section 4).
2.4 Web Personalization
Web personalization is concerned with schemes that
select the type and quantity of content to be shown
to the e-user based on individual profiles.
Personalization applications for e-commerce usually
show products and services the e-shopper did not
ask for, hoping that some of them will catch his or
her attention.
Content-based filtering makes recommendations
based on comparisons between resources and the
user’s profile. Results retrieved are based on their
similarity to what the e-shopper has previously
shown interest. Collaborative filtering selects
products or services that are recommended or used
by the e-shoppers’ peers by identifying groups of
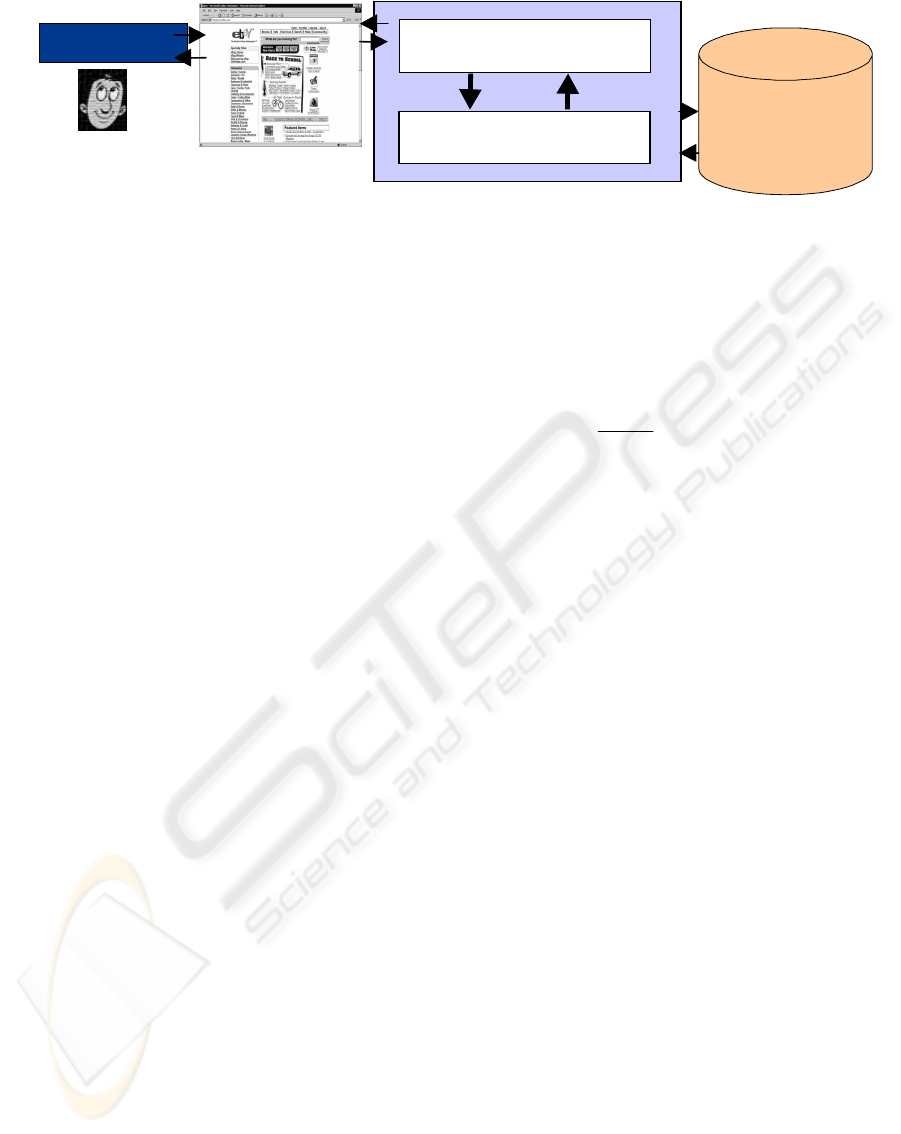
Figure 1
:
The SPOT methodology
Knowledge
Base
Web Client
Mathematical Module
user
Web
Resources
MODELING PREFERENCES ONLINE
257
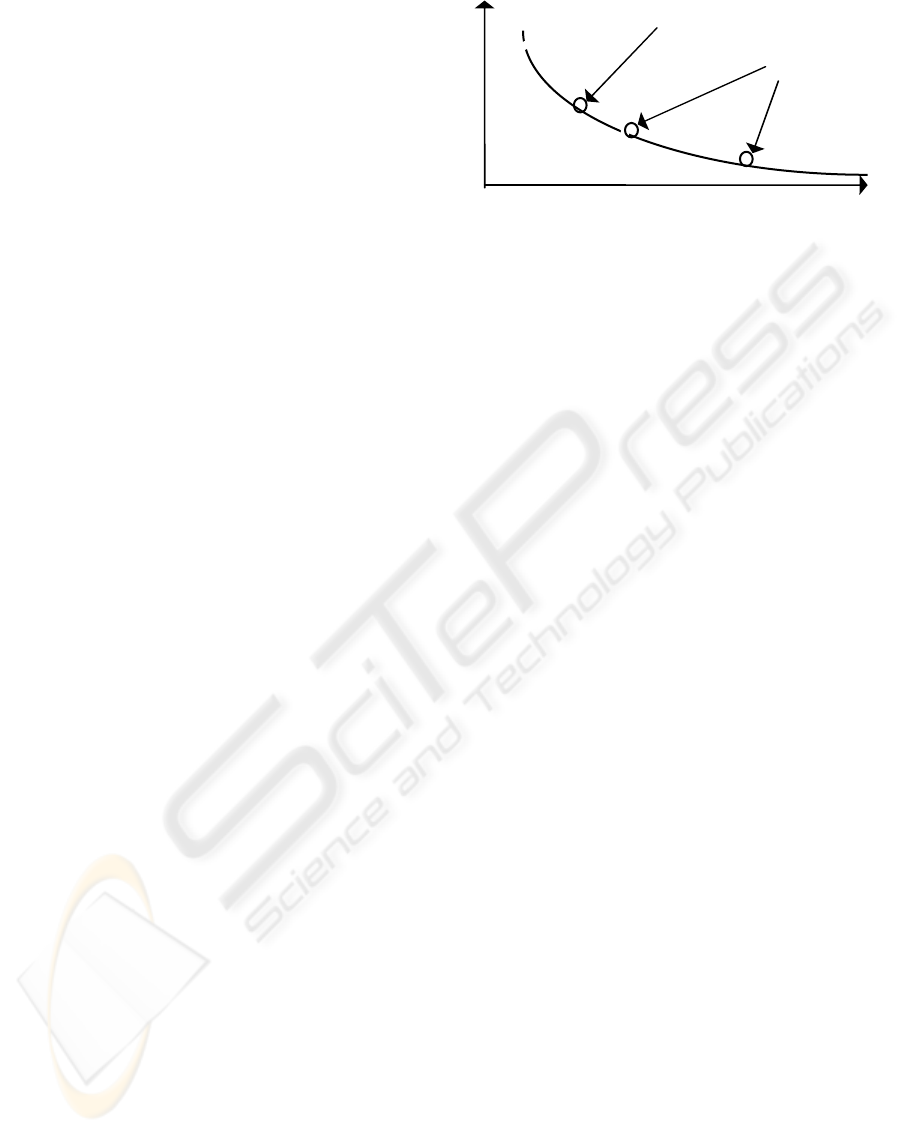
U(x
)
Y
User’s options for
keyword input
Utility curve (search space)
Figure 2: Pictorial representation of utility function
(U(x))
users with similar characteristics and interests
(Cotter & Smyth 2000).
The approach in this paper can be considered
both utility and knowledge-based. Utility-based
because it models utilities of an option; knowledge-
based because it proposes the use of ontologies for
representing knowledge related to online shopping.
Ontologies are knowledge models that retain
conceptualizations that are explicit, consensual, and
conceptual (Gruber 1993). A
LICE (Domingue et al.
2002) is an example of an ontology-based
recommender system.
3 SPOT METHODOLOGY
The Stated Preference Ontology Targeted (SPOT)
methodology (Figure 1) for web personalization uses
the implicit user’s decision function to find the
product or service with the highest likelihood of
being considered by the e-shopper in a given e-
session. While keyword search methods use words
to find related information, S
POT uses the
individual’s decision function (i.e. utility) to search
the web space and find appropriate offers. Figure 2
is a pictorial representation of the search space, i.e.
data points and extrapolation points. One can
understand those points as choice possibilities or
products. The approach suggested in this paper
builds a user profile based on the individual’s utility
curve, instead of those based on isolated points
whose matching product options might not exist.
The core of the methodology is stated preference:
the technique employed to collect individual data on
discrete choices (i.e. how individuals make
decisions). Once enough data is collected, the model
is calibrated using Logit modeling. The results are
coefficients relating product attribute values and
their importance to the users. Those coefficients are
then used to rebuild the utility function for each
alternative of product available online. Those with
the highest likelihood value should be shown to the
user. The two main modules in S
POT are the
knowledge base and the mathematical module. The
knowledge base retains ontologies, (e.g. products,
customers’ profiles, communities); the mathematical
module manipulates algorithms for modeling the
discrete choice data, and for analysis of the results.
3.1 Knowledge Base
We are assuming that within the semantic web,
products and services will be described using
product ontologies. Standards for defining and
classifying goods have already been developed, such
as ISO 10303 (step) and can be used as the basis of
products ontologies. Such ontologies will contain
links to web pages of those companies providing the
service, and to product attributes that customers
might consider important (and therefore use in their
decision-making).
The ontology-based recommender system A
LICE
(Domingue et al. 2002) includes ontologies for
customer, products, typical shopping tasks, and the
external context. Ontologies are populated as they
are linked to the company’s databases. Two
important ontologies in A
LICE are Customers and
Products. Customers ontology defines slots about
customers (their typology, how they use the product,
which attributes are important, etc.). The Product
ontology contains information about the product,
such as type and attributes.
As product ontologies grow, so does the need for
more sophisticated methods to select products to
offer to users. The S
POT methodology can be
implemented on top of e-commerce systems such as
A
LICE (ibid) to address the selection problem. E-
shoppers’ preferences and information about their
decision-making processes would be part of the
customer’s ontology.
Another characteristic of incorporating
knowledge bases to e-commerce systems is the
potential to systematically discover knowledge from
collected data. Kozinets (1999) suggests the
identification of true communities of consumption
by clustering information on individuals’ profiles i.e.
gathered in their buying decision-making processes.
4 SYNTHETIC STUDY
We demonstrate our approach using a theoretical
example of an online search situation where we
compare keyword search with S
POT.
4.1 Methodology
A factorial design was used to gather choice answers
for a simulated customer. The full factorial design
WEBIST 2005 - WEB INTERFACES AND APPLICATIONS
258
guarantees that calibration results are significant.
Alternative options were built with the purpose of
showing how the proposed methodology compares
with the traditional database search. The data
contains choice sets with three alternatives each,
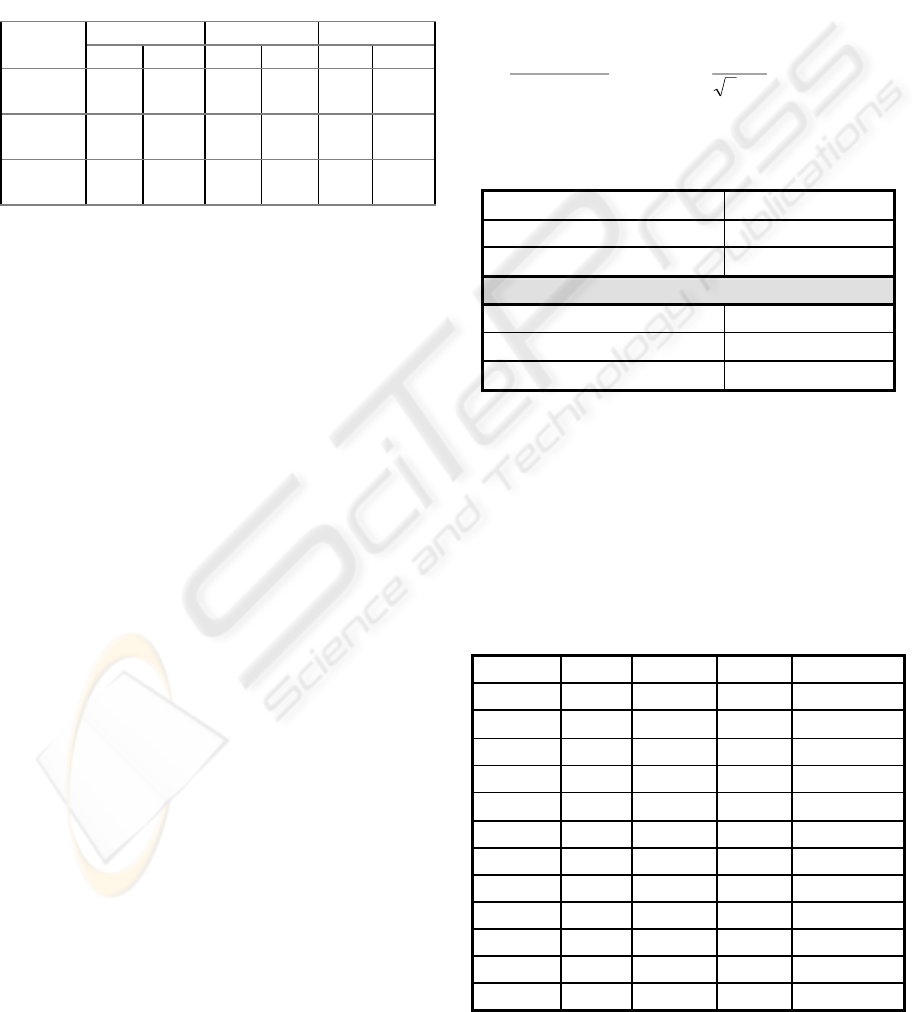
which are evaluated in three attributes (Table 1:
Attributes 1, 2, and 3). For instance, a transport
option could be characterized by its cost, travel time,
and headway. High and low (Table 1) indicate
extreme ranges for the options.
Table 1 Attribute levels for the 512 choice scenarios
Alternative 1 Alternative 2 Alternative 3
low high low high low high
Attribute
1
30 80 40 100 50 120
Attribute
2
20 45 15 30 10 40
Attribute
3
30 15 60 20 70 30
The synthetic data is created based on a full factorial
design so that our simulated customer made 512
hypothetical discrete choices. Of course, in a real
situation there are other methods (Fowkes &
Shinghal 2002) that can be employed to reduce this
number to an acceptable value and still show good
calibration performance.
The simulation approach is based on the fact that
we know the deterministic part of the utility function
used by decision makers in a choice situation. The
random term is the unknown part of the utility but
we know its distribution mean and standard
deviation. The total utility for each alternative is
found by adding the random term (Weibull
distributed) to the deterministic utility component
(see Equation 1). A linear function that adds the
option attribute values by its respective weight is
employed to find the deterministic component. The
probabilistic part is simulated using the method of
the inverse function. Thus pseudo-random numbers
are created according to the inverse of the Weibull
probability distribution (Equation 4) and used as the
behaviour of our simulated individual regarding his
choices. Following is a brief explanation of the
Weibull probability distribution as the base to create
data that follows Logit assumptions.
4.1.1 Weibull Probability Distribution
The random part of the utility refers to unknown
variables influencing the choice process, from the
analyst point of view. For instance, taste variation.
Logit modeling is based on the assumption that such
random term is Weibull (or Extreme Value)
distributed (Luce 1959) as in Equation 3. Therefore,
knowing the inverse of the cumulative Weibull
distribution function (Equation 4), it is possible to
recreate a SP experiment synthetically. This
procedure allows one to compare methodologies on
the bases of what the answers would be.
F
e
e()
()
ε
µ
ε
η
=
−
−−
Equation(3)
Assuming η=0, the inverse of that function
(Equation 4) results in a random number (ε) which is
Weibull distributed. This number would account for
the uncertainties in the modeling a process analysts
do not know (though known by the decision-maker).
ε
µ
µ
π
σ
=
−−ln( ln( ))
*
u
, =
6
Equation(4)
Where u = a uniformly random number; σ =
standard deviation; η = location parameter.
Table 2: Calibration results for SP discrete choice data
Likelihood -176.7801
Rho-Squared 0.6857
N. iterations 7
Coefficients
Attribute 1 -0.03697 (-9.2)
Attribute 2 -0.03057 (-12)
Attribute 3 -0.03032 (-5.5)
The synthetic data (composed of 512 choice
scenarios and the choice) is then used to calibrate a
Logit model that reveals the weights the customer
used to make the choice. The performance of the
calibration is investigated using a well-known
econometric test, Rho squared. Results from
calibrating our synthetic data are shown in Table 2.
Rho squared is quite high and coefficients are
significant, as expected (since we are using data that
follows Logit modeling).
Table 3: Choice options and respective utility values
Option
Attr. 1 Attr. 2 Attr. 3 Utility*
1
30 20 15 -7.6779
2
30 45 30 -15.7752
3
30 45 30 -15.7752
4
30 45 30 -15.7752
5
30 45 30 -15.7752
6
100 30 20 -13.4744
7
40 15 60 -7.8835
8
120 40 30 -17.574
9
50 10 70 -7.0279
10
50 10 30 -5.8151
11
50 40 70 -16.1989
12
50 40 30 -14.9861
MODELING PREFERENCES ONLINE
259
Additionally, coefficients used to create the data
could be roughly recovered. Therefore, we are using
these coefficients to evaluate the alternative options
in Table 3. Observe that in our special case we know
the true coefficients employed to create the data. In
real situations those coefficients are only known
employing a mathematical model. A major
advantage of using synthetic data is that we know
beforehand the deterministic part of the utility
function and the parameters used to create the
random part. Then, we can evaluate the results
comparing them with the known function used to
create the data. The following tables show the results
from calibrating the SP synthetic dataset.
4.2 Results
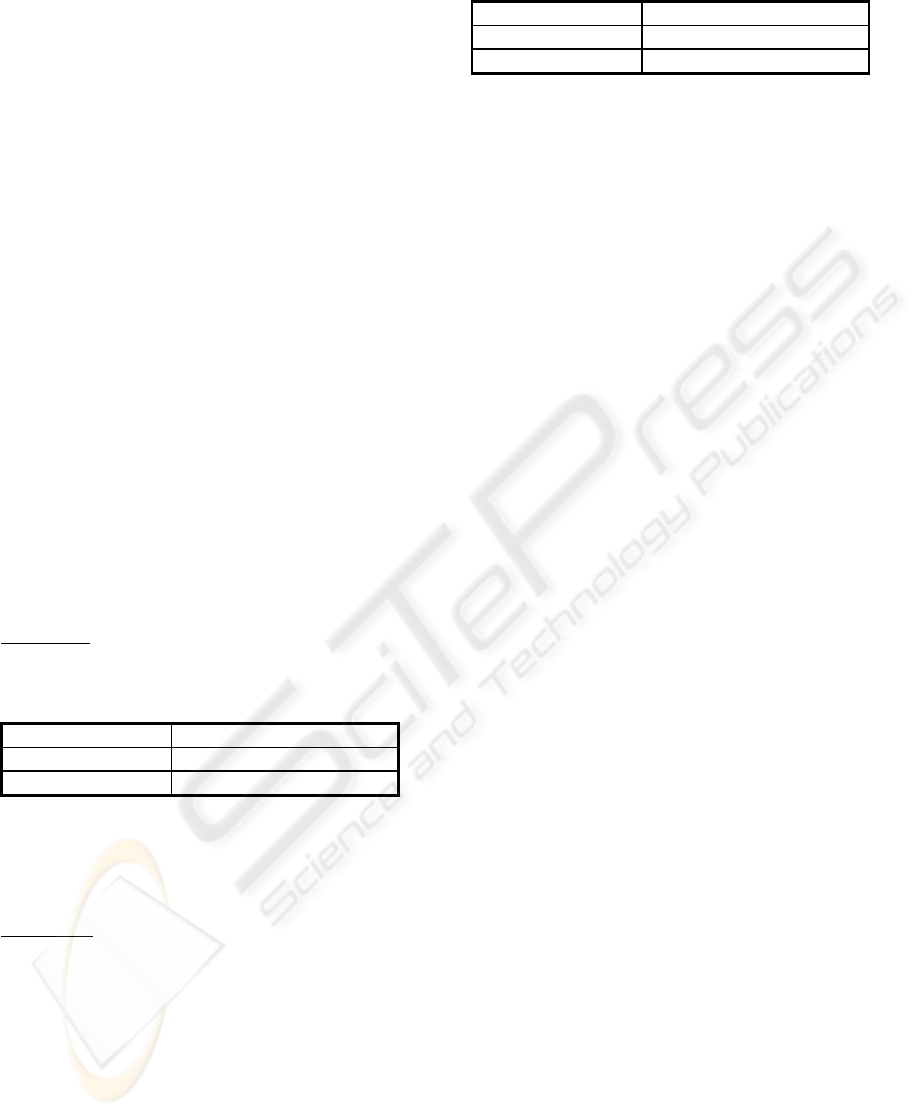
Table 3 shows for each option (1 to 12) their
attribute values and their respective utilities. For
instance, the values of Attributes 1, 2 and 3 for
Option 1, are 30, 20 and 15, respectively. In case of
a transport option it could be 30 minutes travel time,
20 minutes waiting time, and price of 15 USD, or
nominal values. Table 3 is the database of available
options for a searching system.
Given the database of 12 possible choices shown
in Table 3, we examine Situation 1 and Situation 2,
where we employ respectively keyword search and
S
POT. Results are shown in Tables 4 and 5.
Situation 1
: The user inputs a keyword that matches
at least one of the available options. For instance,
value of 40 to Attribute 1.
Table 4: Results for Attribute 1 = 40
Method Result shown to the user
Keyword search Alternative 7 (40, 15, 60)
SPOT Alternatives 9, 10 and 1
Keyword search shows Alternative 7 as its own
possible match. S
POT methodology using the value
of the utility of all alternatives, would show three
results corresponding respectively to 1
st
, 2
nd
, and 3
rd
places.
Situation 2
: The same user inputs a keyword that
does not match any of the available options (quite
common on the Internet for travel services like car
rental). For instance, value of 60 to Attribute 1.
In Situation 2, the keyword search method does
not return any possibility. On the other hand, S
POT
methodology returns 3 possible alternatives. In this
case, we are employing a compensatory model and
the three attributes are evaluated at once. However, a
non-compensatory model can also be employed to
perform a pre-selection of maximum or minimum
attribute values. As an example, the user would not
accept to pay more than US$ 50 for the trip.
Table 5: Results for Attribute 1 = 60
Method Result shown to the user
Keyword search None
SPOT Alternatives 9, 10 and 1
Given results shown on Table 3, the best choice
from the customer decision-process viewpoint would
be Option 10 (the highest utility), which is
highlighted.
In this theoretical example, we illustrated how
using knowledge about the user’s decision-making
process can improve the quality of the online search
results. For instance, in case of Situation 1, only one
alternative would be shown to the user (Option 7 in
Table 3). This alternative would not even be
considered by the user as there are others with
higher utility value (Table 3). On the other hand,
Situation 2 would show no results to the user; as the
criteria do not match any of the alternatives in the
database (Table 5). This is quite a common situation
in e-commerce sites.
5 DISCUSSION
A recommender system is one that, based on certain
criteria, recommends products or services. Current
personalization schemes are mainly focused on
delivering contents that are either similar to users’
profiles (i.e. content-based) or are recommended by
their peers (i.e. collaborative). Information on e-
shoppers (e.g., history, profile, preferences) is used
to feed the personalization scheme. A
comprehensive review of recommender systems is
given by Burke (2002). Being utility-based, this
paper addresses a slightly different problem: how to
help the e-shopper decide between the choices
available on the Internet.
Usually, the information gathered over the
Internet from recommender systems is not used for
other purposes than to feed the personalization
scheme. These schemes do not address ways to
improve the company’s decision strategies (such as
product design), or how it could help the e-shopper’s
choice decision-making process. Helping the e-
shopper in this decisive moment has the potential
not only to increase the company’s sales but also to
improve the knowledge about their customers’
values. That is often a strategy used in physical
stores where the sales person often has a decisive
impact on the choice.
Figure 3 illustrates a real situation of online car
rental pictured on a shopbot web page. Shopbot is an
e-commerce portal where users have access to
different web service providers and can compare
their offers as well as buy them. In this web site, the
WEBIST 2005 - WEB INTERFACES AND APPLICATIONS
260

Figure 3: Online car rental shopbots
e-shopper begins the search process filling out a
form with some parameters (e.g., car size, pick-up
day, pick-up location). Those parameters are used to
search the server database for available options.
Quite often the search is unsuccessful at the first
time. There are different reasons for that. For
example, the specific supplier may not have
branches on the pick-up location, or the requested
car size is not available. Eventually, the user has to
change the search parameters a couple of times in
order to find one offer. When the user finally
manages to find some offers, she or he has to reason
and decide for one of them or none. It might be the
case that by evaluating the choices available, the
user considers that all offers are overpriced
compared to the prices of the cars and decides not to
buy the service. Therefore, instead of hiring a car,
the individual might decide to use local public
transport, or a taxi service. Note that decision
processes vary according to the individual and the
situation. Whether the individual is shopping for
himself or for a company may change the decision
model.
From the perspective of the car rental company, it
could be a lost sale. If only the car-rental company
new how individuals evaluate the different attributes
of the service, they would try to show alternative
options from the customer perspective. Maybe
showing an offer with a better car would give the
correct balance between the price of the car and the
rental value.
In the example above, we are assuming that the
user evaluates the car rental options considering the
price of the vehicle being hired and alternative ways
of transport (such as public transport and taxi). Other
decision models for this service would consider car-
size within an acceptable price-range. In the car
rental business, companies are often bounded to
specific carmakers. Moreover, they have prices tied
to combination offers that force the consumer to
purchase at least two services. A web portal offering
such car rental services would benefit from the S
POT
approach, as it would always show options regarded
by the user as relevant. With currently used
methods, the search usually has to be repeated a
couple of times with different keywords before a
reasonable option comes up as a result.
Furthermore, the S
POT methodology is based on
knowledge about how customers evaluate product
characteristics, e.g. what sort of decision process
they perform, which attributes and variables they
consider. This is an application with potential to take
full advantage of the semantic web infrastructure. It
can search semantic information on products (i.e.
from products ontology) and service information,
and populate ontologies on customers’ profile.
Although ontologies are seen as the core of the
semantic web, actual applications are still in their
infancy. An initiative for transforming knowledge
about products and services into a world common
ontology is ISO 10303, an International Standard for
product data representation and exchange. However,
there is still need for technologies that enable
application systems to exchange and share data
about technical products. Their product
classification cannot be used as a complete ontology,
as the definitions tend to be semantically weak.
6 CONCLUSIONS
The SPOT methodology discussed in this paper uses
the evaluation of the online alternatives based on the
e-shopper decision process. This personalization
scheme will prompt advantageous options that the e-
shopper would not find otherwise. The main purpose
of S
POT is not to make recommendations on
products that users may or may not be interested in.
S
POT’s main contribution is to help the user with the
decision-making on products he needs but have
difficulties choosing between the large amounts
available on the Internet. This approach has the
potential to substantially improve the relevance of
the results shown to the e-shopper in an e-commerce
session and therefore increase the likelihood of a
sale. Even though the user would be anonymous
during the session, results from the system allow the
company to know the trade-offs individuals make
between the characteristics of a product or service
and use them to forecast online demand, improve
products, etc.
This paper discusses a methodology that uses
economic theory on discrete choices to link e-
shoppers’ decision-making process to available
online options. The approach suggested in this paper
builds a user profile based on the individual’s utility
curve, instead of isolated points (the user’s criteria)
whose options might not exist.
MODELING PREFERENCES ONLINE
261

The main input to the proposed methodology is the
discrete choice data, which is collected from
interactive Stated Preference “games” that the e-
shopper agrees to participate. The data is then used
to calibrate a Logit model that will reveal the trade-
offs the e-shopper employed in his or her choice
decision-making process. Afterwards, these results
are employed to search for the available options and
calculate their values as the customer himself would.
Options with high utility value are then shown to the
e-shopper.
The benefits of using the methodology are
twofold. First, it has the potential to increase
customer satisfaction and therefore the likelihood of
sales and revisits. Second, the information on
customer’s choice decision-making process gives the
company insights on how to improve the business
(such as product design and sales). The
implementation of this methodology requires
investigation of the user’s decision-making process
for each product and the development of friendly
interfaces to reduce the time to collect stated
preference data online.
The major challenge of implementing S
POT is the
data gathering. The approach’s input is data from an
interactive SP game that demands customers’ time.
Customers have to be convinced that providing
answers to the interactive game will give them a
better service. A friendly interface can help
overcome this problem by reducing the cognitive
effort needed for the task.
Another alternative would be to insert an
additional reasoning step and try to match a current
e-shopper with a previously recorded decision-
making model. This match could be based on
similarity (i.e. using case-based reasoning) and
would reduce the number of required questions to
elicit the e-shopper’s preferences.
We should also consider that customers may not
be interested in wasting time to take part in a SP
game that evaluates low priced products or services.
This requires an analysis of the customer’s value of
time to discover the threshold from which they
would be willing to compare options further. As a
guideline, the company could employ this
methodology only to the most profitable or high
priced 20% products, which often represents
approximately 80% of the company’s profit.
REFERENCES
Ardissono, L. & Godoy, A. 2000. Tailoring the Interaction
with Users in Web Stores. User Modeling and User-
Adapted Interaction, 10: 251-303.
Ben-Akiva, M. & Lerman, R. 1985. Discrete Choice
Analysis. MIT Press. Cambridge, MA.
Burke, R. 2000. Knowledge-Based Recommender
Systems. In A. Kent (ed.), Encyclopedia of Library
and Information Systems, 69, 32. Marcel Dekker. New
York:
Burke, R. 2002. Hybrid Recommender Systems: Survey
and Experiments. User Modeling and User-Adapted
Interaction, 12(4): 331-370.
Cotter, P. & Smyth, B. 2000. PTV: Intelligent
Personalised TV Guides. Proceedings of Innovative
Applications of Artificial Intelligence, pp. 957-964.
AAAI Press/ The MIT Press.
De Carvalho, M. 1998. A Comparison of Neural Networks
and Econometric Discrete Choice Models in
Transport. Institute for Transport Studies, University
of Leeds, UK. (PhD-thesis)
Domingue, J., Martins, M., Tan, J., Stutt, A., Pertusson, H.
2002. Alice: Assiting Online Shoppers through
Ontologies and Novel Interface Metaphors. (In
Gómez-Pérez, A. & Benjamins, V. R. (eds.)
Knowledge Engineering and Knowledge Management.
Ontologies and the Semantic Web. LNCS, 2473.
Berlin: Springer. p. 335-351.)
Fowkes, T. & Shinghal, N. 2002. The Leeds Adaptive
Stated Preference Methodology. (In Danielis, R. (ed.)
Freight Transport Demand and Stated Preference
Experiments, F. Angeli, Milan.)
Gruber, T. R. 1993. A Translation Approach to Portable
Ontology Specifications. Knowledge Acquisition, 5(2):
199-220.
Kocur, G., Adler, T., Hyman, W. & Aunet, B. 1982. Guide
to Forecasting Travel Demand with Direct Utility
Assessment. Report No. UMTA-NH-11-0001-82,
Urban Mass Transportation Administration, US
Department of Transportation, Washington, DC.
Kozinets, R. V. 1999. E-Tribalized Marketing: the
Strategic Implications of Virtual Communities of
Consumption. European Management Journal, 17 (3):
252-264.
Luce, R. D. 1959. Individual Choice Behavior. New York.
John Wiley & Sons, Inc.
Louviere, J. J. 1988. Analyzing Decision Making: Metric
Conjoint Analysis. Newbury Park, CA: Sage
Publications, Inc.
McGinty, L. & Smyth, B. 2002. Comparison-Based
Recommendation. (In Craw, S. and Preece, A. (eds.)
Advanced in Case-Based Reasoning. LNAI, 2416.
Berlin, Springer. p. 575-589.)
Pearmain, D. & Kroes, E. 1990. Stated Preference
Techniques: a Guide to Practice. Steer Davies &
Gleave, UK.
WEBIST 2005 - WEB INTERFACES AND APPLICATIONS
262
